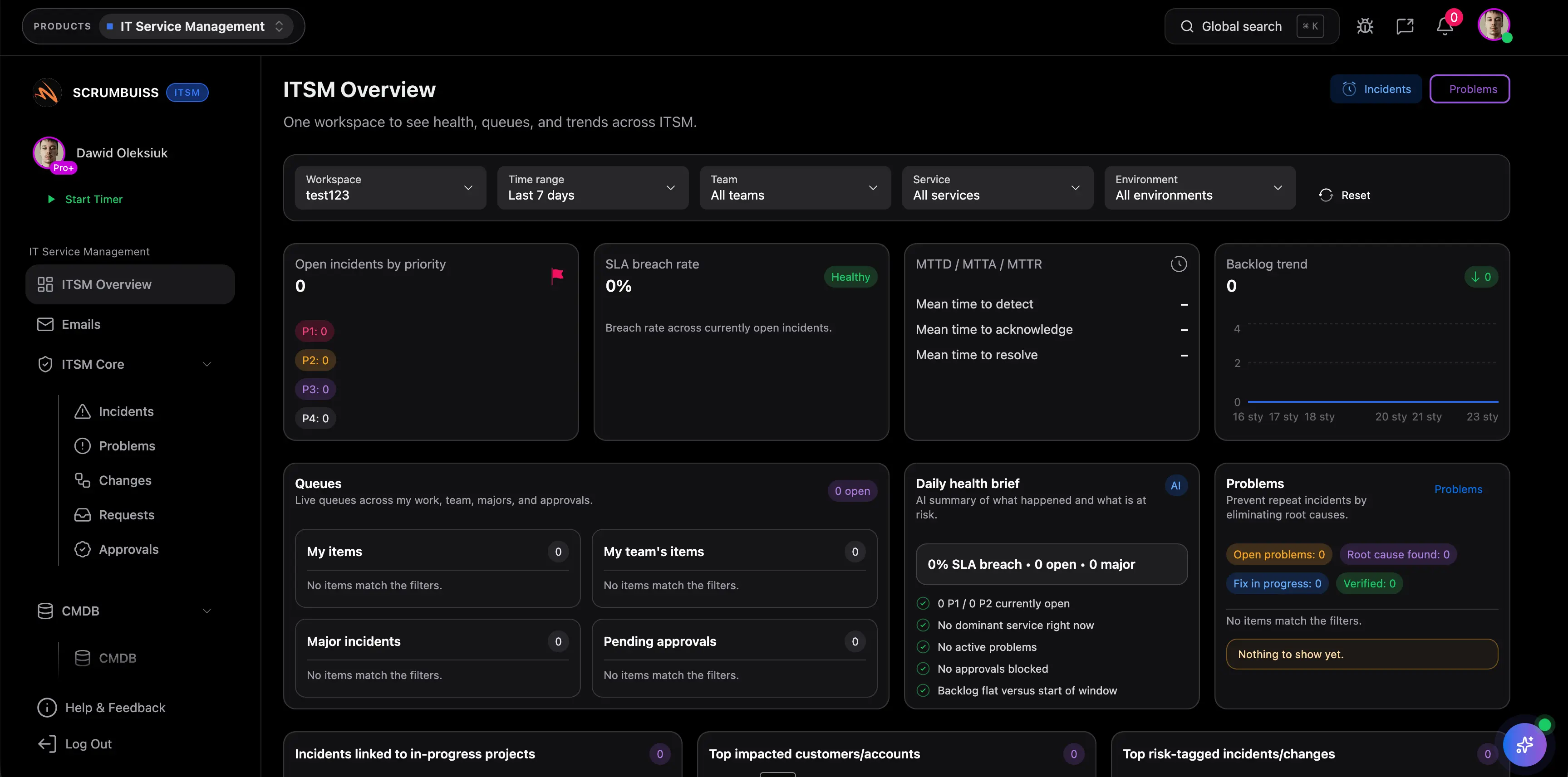
Incident Postmortem najlatwiej ocenic wtedy, gdy test jest podlaczony do prawdziwej sciezki delivery. Ponizsze notatki pomagaja porownac Scrumbuiss z tym, jak zespol faktycznie planuje, przekazuje, raportuje i reviewuje prace projektowa.
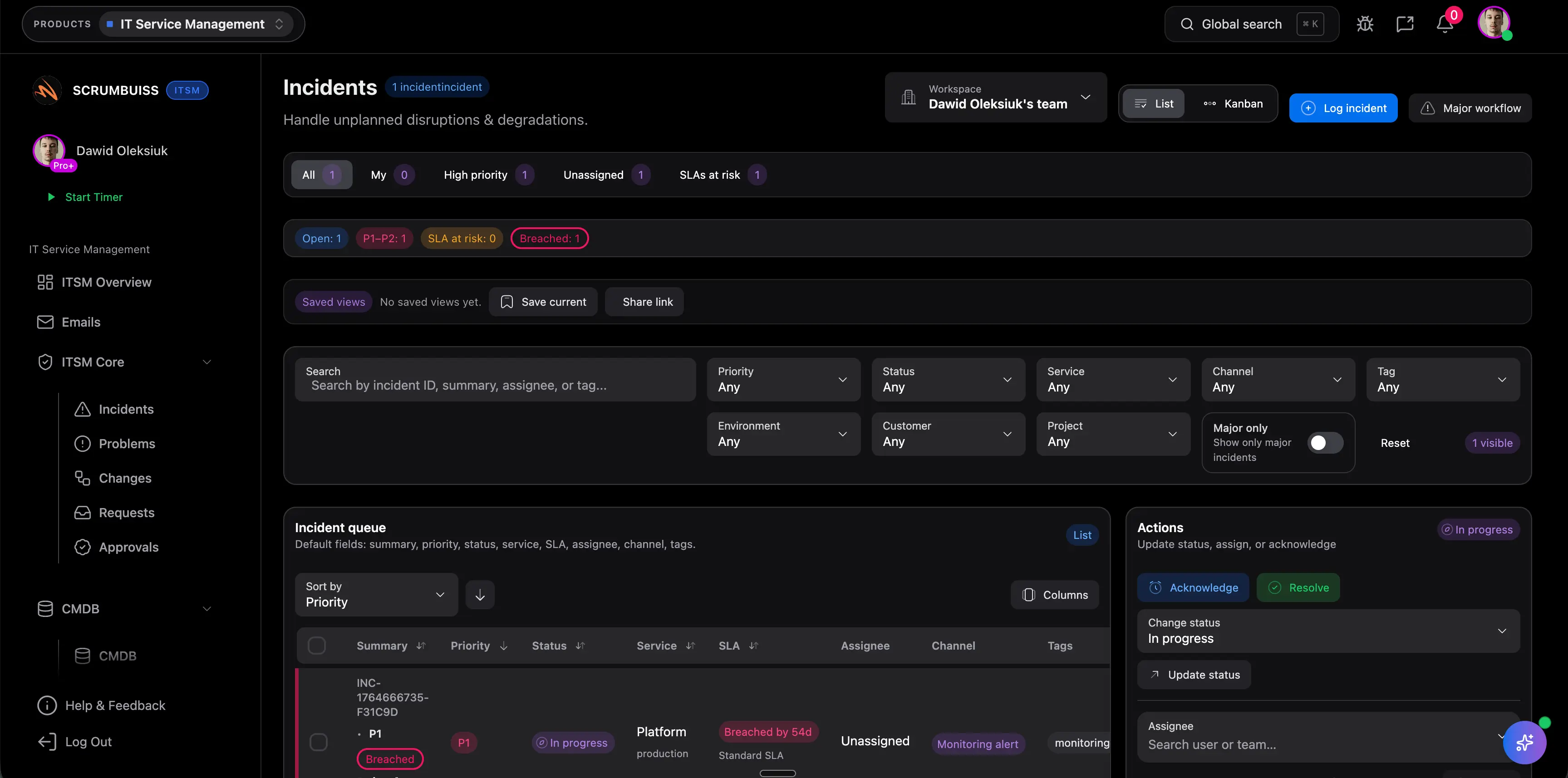
Kiedy zespol ocenia Incident Postmortem, najwazniejsze pytanie brzmi, czy kolejny wlasciciel widzi zakres, terminy, blokery, pliki i akceptacje bez odbudowywania calej historii z czatu albo notatek ze spotkan. Dzieki temu ocena pozostaje zwiazana z prawdziwa praca, a nie z generyczna lista funkcji. To dobra baza dowodowa dla pierwszego pilota.
Praktyczny pilot dla Incident Postmortem powinien obejmowac kontekst operacyjny, poniewaz codzienna praca, status, pewnosc delivery i zobowiazania wobec klienta pozostaja polaczone zamiast rozpadac sie miedzy tablice, arkusz i osobny raport. Taki pilot latwiej tez punktowac, bo zespol moze porownac stary i nowy workflow krok po kroku. To dobra baza dowodowa dla pierwszego pilota.
Najmocniejszym sygnalem dla Incident Postmortem nie jest kolejny statyczny ekran, ale dowod, ze konfiguracja jest na tyle prosta, ze account leadzi, project managerowie, wykonawcy i interesariusze uzywaja jej takze po pierwszym tygodniu. Bez tego dowodu rollout czesto tworzy kolejna warstwe raportowania zamiast ograniczyc koordynacje. To dobra baza dowodowa dla pierwszego pilota.
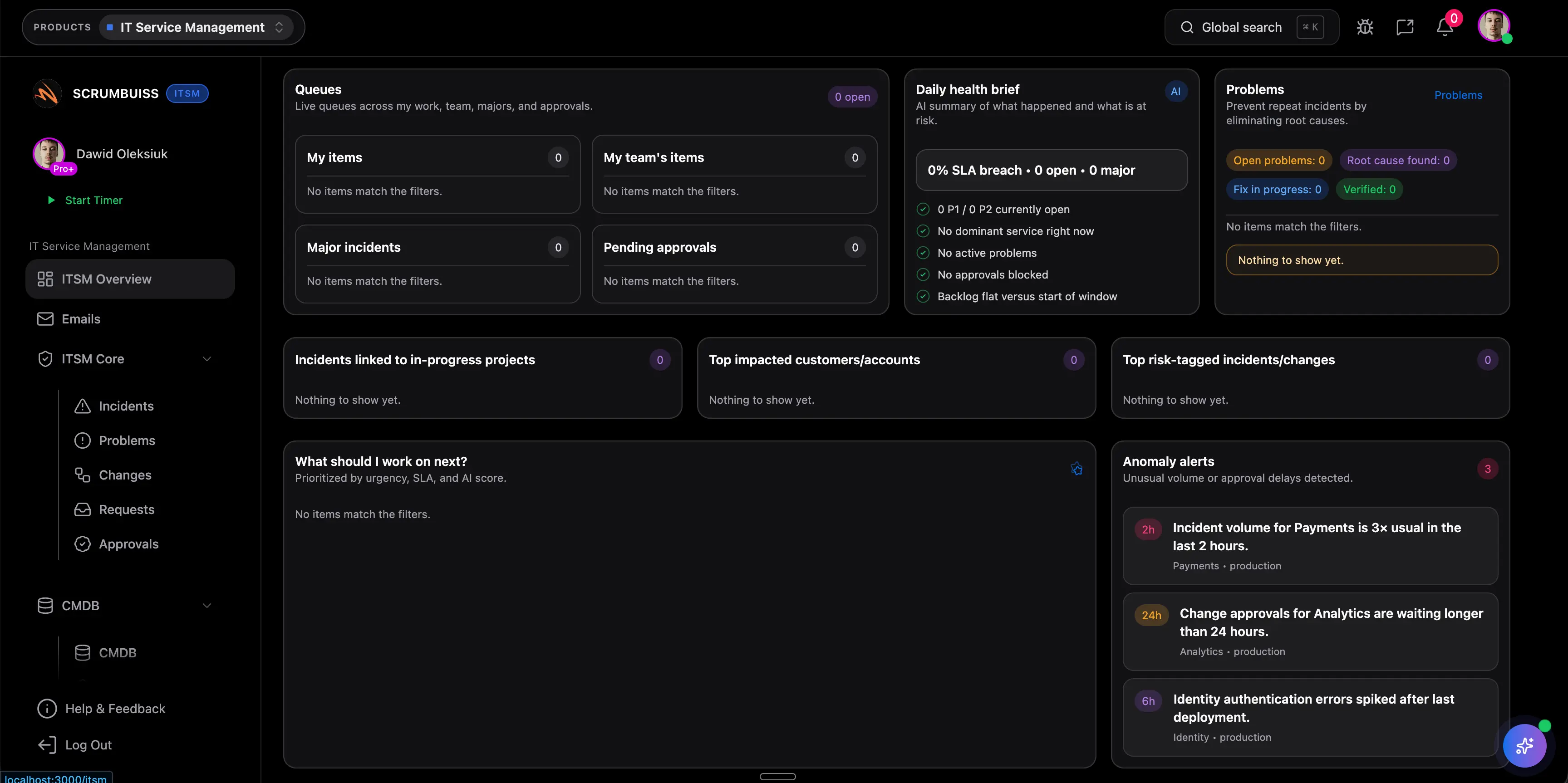
Przed wyborem narzedzia dla Incident Postmortem warto opisac, jak obecny proces obsluguje jakosc raportowania i czy liderzy potrafia odroznic realne ryzyko delivery od zwyklego szumu aktywnosci, bo estymacje, ownership, daty, obciazenie i komentarze sa oceniane razem. Scrumbuiss trzyma te sygnaly blisko pracy, aby obraz operacyjny pozostawal czytelny. To dobra baza dowodowa dla pierwszego pilota.
Kiedy zespol ocenia Incident Postmortem, najwazniejsze pytanie brzmi, czy klienci albo zewnetrzni interesariusze dostaja czytelny status bez dostepu do kazdego wewnetrznego szczegolu operacyjnego. Dzieki temu ocena pozostaje zwiazana z prawdziwa praca, a nie z generyczna lista funkcji. To dobra baza dowodowa dla pierwszego pilota.
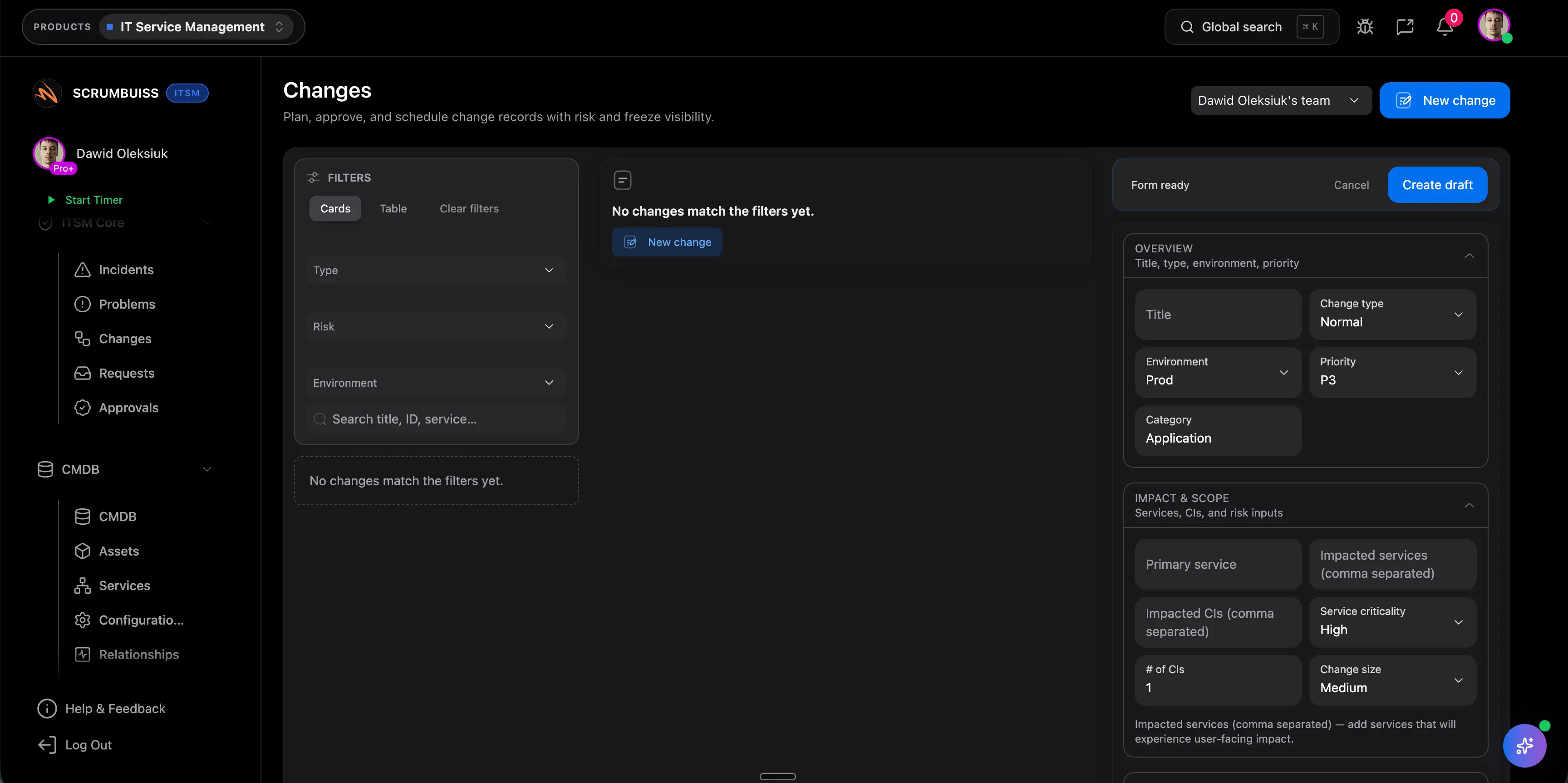
Praktyczny pilot dla Incident Postmortem powinien obejmowac ustrukturyzowany intake, poniewaz nowa praca trafia do systemu z wystarczajacym kontekstem, aby ja przekierowac, ustalic priorytet i rozpoczac delivery bez kolejnej rundy wyjasnien. Taki pilot latwiej tez punktowac, bo zespol moze porownac stary i nowy workflow krok po kroku. To dobra baza dowodowa dla pierwszego pilota.
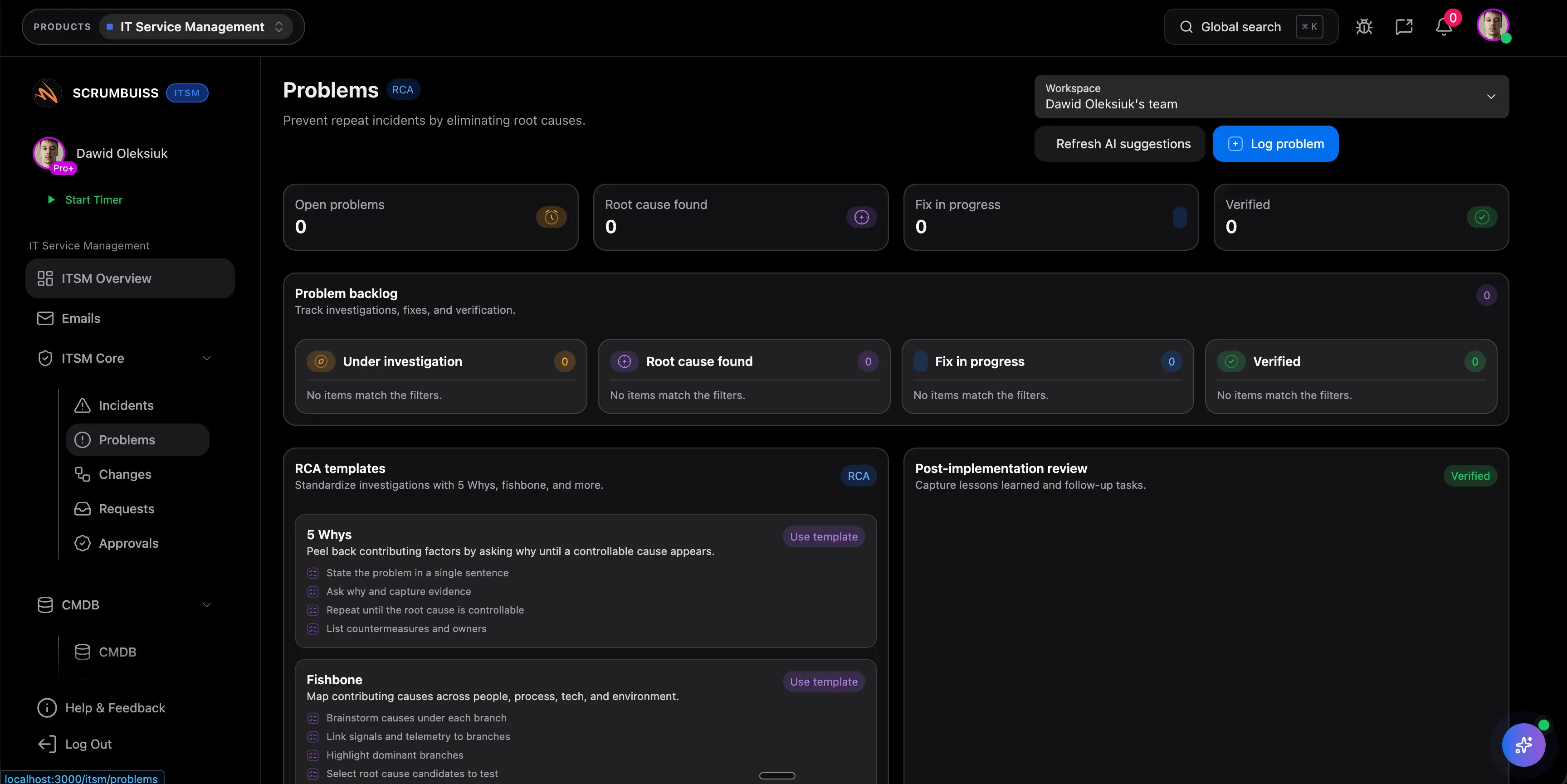
Najmocniejszym sygnalem dla Incident Postmortem nie jest kolejny statyczny ekran, ale dowod, ze briefy, zalaczniki, komentarze i akceptacje pozostaja blisko zadan oraz kamieni milowych, na ktore realnie wplywaja. Bez tego dowodu rollout czesto tworzy kolejna warstwe raportowania zamiast ograniczyc koordynacje. To dobra baza dowodowa dla pierwszego pilota.
Przed wyborem narzedzia dla Incident Postmortem warto opisac, jak obecny proces obsluguje planowanie capacity i czy zespol widzi, czy praca blokuje sie przez ludzi, zaleznosci, review albo nieplanowane incydenty zanim termin zacznie byc zagrozony. Scrumbuiss trzyma te sygnaly blisko pracy, aby obraz operacyjny pozostawal czytelny. To dobra baza dowodowa dla pierwszego pilota.
Kiedy zespol ocenia Incident Postmortem, najwazniejsze pytanie brzmi, czy pierwsze wdrozenie moze zaczac sie od jednego prawdziwego workflowu, potwierdzic model pracy i dopiero potem rosnac bez pelnej przebudowy. Dzieki temu ocena pozostaje zwiazana z prawdziwa praca, a nie z generyczna lista funkcji. To dobra baza dowodowa dla pierwszego pilota.
Praktyczny pilot dla Incident Postmortem powinien obejmowac governance, poniewaz uprawnienia, ownership, reguly statusow i sciezki eskalacji sa jasne dla managerow, wykonawcow, klientow i osob od procurementu. Taki pilot latwiej tez punktowac, bo zespol moze porownac stary i nowy workflow krok po kroku. To dobra baza dowodowa dla pierwszego pilota.
Najmocniejszym sygnalem dla Incident Postmortem nie jest kolejny statyczny ekran, ale dowod, ze zespol ustala, ktore sygnaly maja znaczenie, na przyklad cycle time, odchylenie estymacji, otwarte ryzyka, spoznione review, blokery i rework po handoffie. Bez tego dowodu rollout czesto tworzy kolejna warstwe raportowania zamiast ograniczyc koordynacje. To dobra baza dowodowa dla pierwszego pilota.
Przed wyborem narzedzia dla Incident Postmortem warto opisac, jak obecny proces obsluguje dopasowanie automatyzacji i czy przypomnienia, reguly routingu i follow-upy zmniejszaja reczna koordynacje bez ukrywania odpowiedzialnosci za wynik. Scrumbuiss trzyma te sygnaly blisko pracy, aby obraz operacyjny pozostawal czytelny. To dobra baza dowodowa dla pierwszego pilota.
Kiedy zespol ocenia Incident Postmortem, najwazniejsze pytanie brzmi, czy podlaczone narzedzia zachowuja role zrodla prawdy, a Scrumbuiss utrzymuje czytelna narracje projektu, nastepna akcje i update dla interesariuszy. Dzieki temu ocena pozostaje zwiazana z prawdziwa praca, a nie z generyczna lista funkcji. To dobra baza dowodowa dla pierwszego pilota.
Praktyczny pilot dla Incident Postmortem powinien obejmowac review bezpieczenstwa, poniewaz sprawdzenie dostawcy, role, udostepnianie zewnetrzne i pytania procurementu sa obslugiwane odpowiednio wczesnie, aby nie opoznic pilota. Taki pilot latwiej tez punktowac, bo zespol moze porownac stary i nowy workflow krok po kroku. To dobra baza dowodowa dla pierwszego pilota.
Najmocniejszym sygnalem dla Incident Postmortem nie jest kolejny statyczny ekran, ale dowod, ze strona powinna pomagac zdecydowac, co testowac najpierw, jakie dowody zebrac i ktory sasiedni workflow sprawdzic przed szerszym rolloutem. Bez tego dowodu rollout czesto tworzy kolejna warstwe raportowania zamiast ograniczyc koordynacje. To dobra baza dowodowa dla pierwszego pilota.
Przed wyborem narzedzia dla Incident Postmortem warto opisac, jak obecny proces obsluguje utrzymanie w czasie i czy model pracy pozostaje czytelny, gdy zespol dodaje kolejne projekty, klientow, zaleznosci albo warstwy raportowania. Scrumbuiss trzyma te sygnaly blisko pracy, aby obraz operacyjny pozostawal czytelny. To dobra baza dowodowa dla pierwszego pilota.
Kiedy zespol ocenia Incident Postmortem, najwazniejsze pytanie brzmi, czy kolejny wlasciciel widzi zakres, terminy, blokery, pliki i akceptacje bez odbudowywania calej historii z czatu albo notatek ze spotkan. Dzieki temu ocena pozostaje zwiazana z prawdziwa praca, a nie z generyczna lista funkcji. Warto sprawdzic to ponownie, gdy workflow obejmie wiecej zespolow, gosci albo update'y dla klienta.
Praktyczny pilot dla Incident Postmortem powinien obejmowac kontekst operacyjny, poniewaz codzienna praca, status, pewnosc delivery i zobowiazania wobec klienta pozostaja polaczone zamiast rozpadac sie miedzy tablice, arkusz i osobny raport. Taki pilot latwiej tez punktowac, bo zespol moze porownac stary i nowy workflow krok po kroku. Warto sprawdzic to ponownie, gdy workflow obejmie wiecej zespolow, gosci albo update'y dla klienta.