To są pytania, na które zespoły zwykle muszą odpowiedzieć, zanim ITSM stanie się częścią realnego rytmu operacyjnego.
Na co zespoły powinny patrzeć najpierw przy wyborze oprogramowania ITSM?
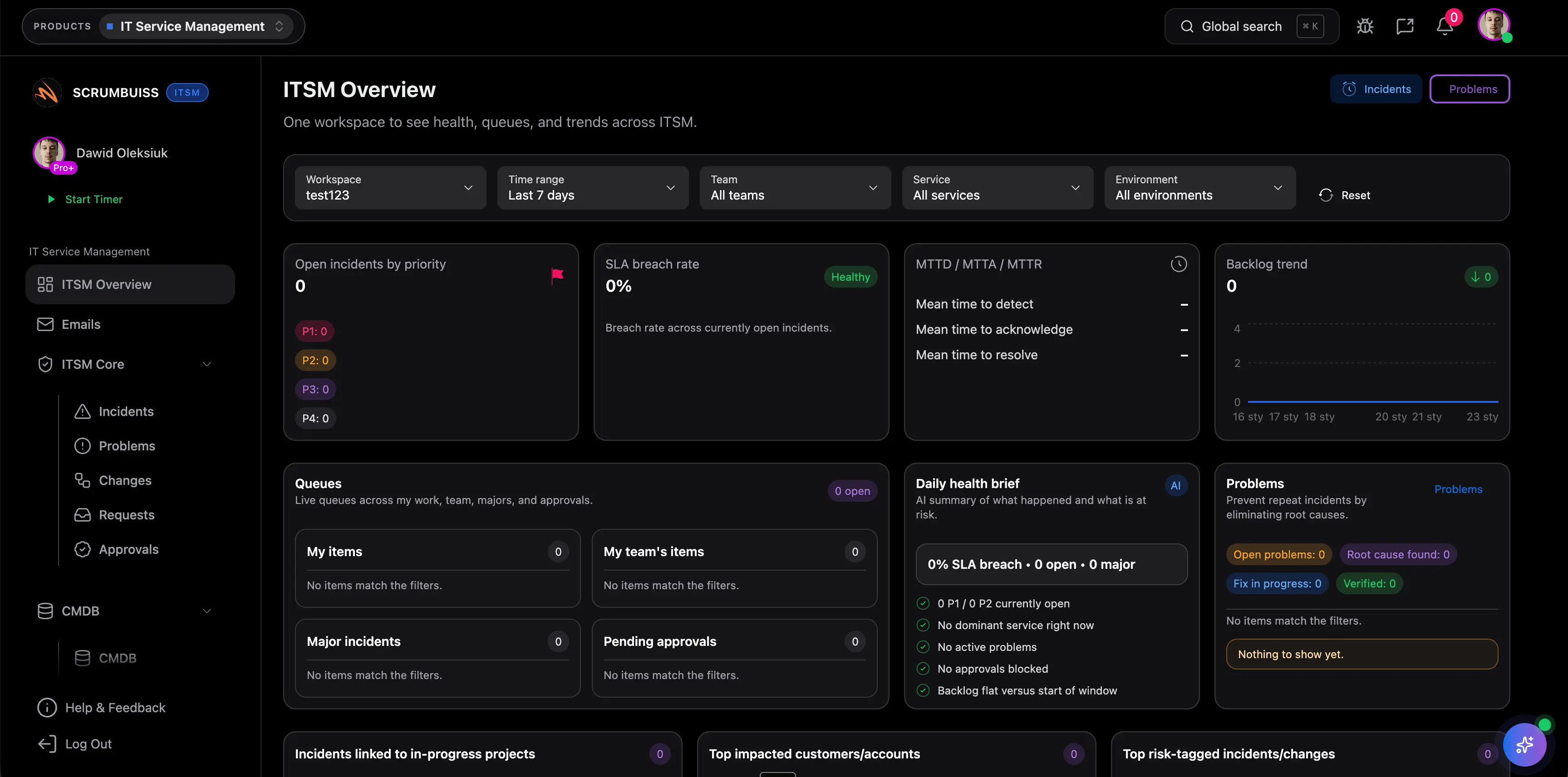
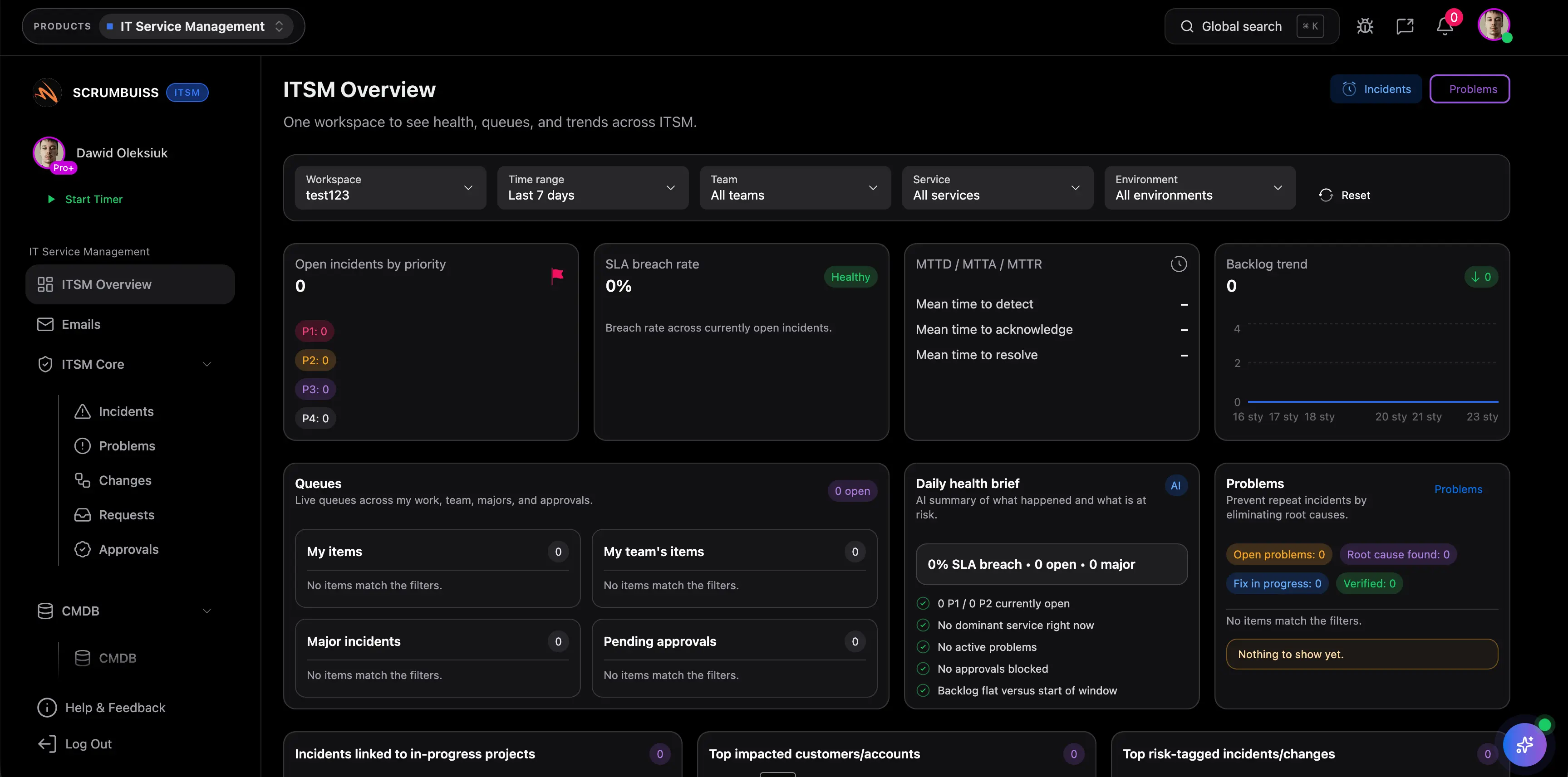
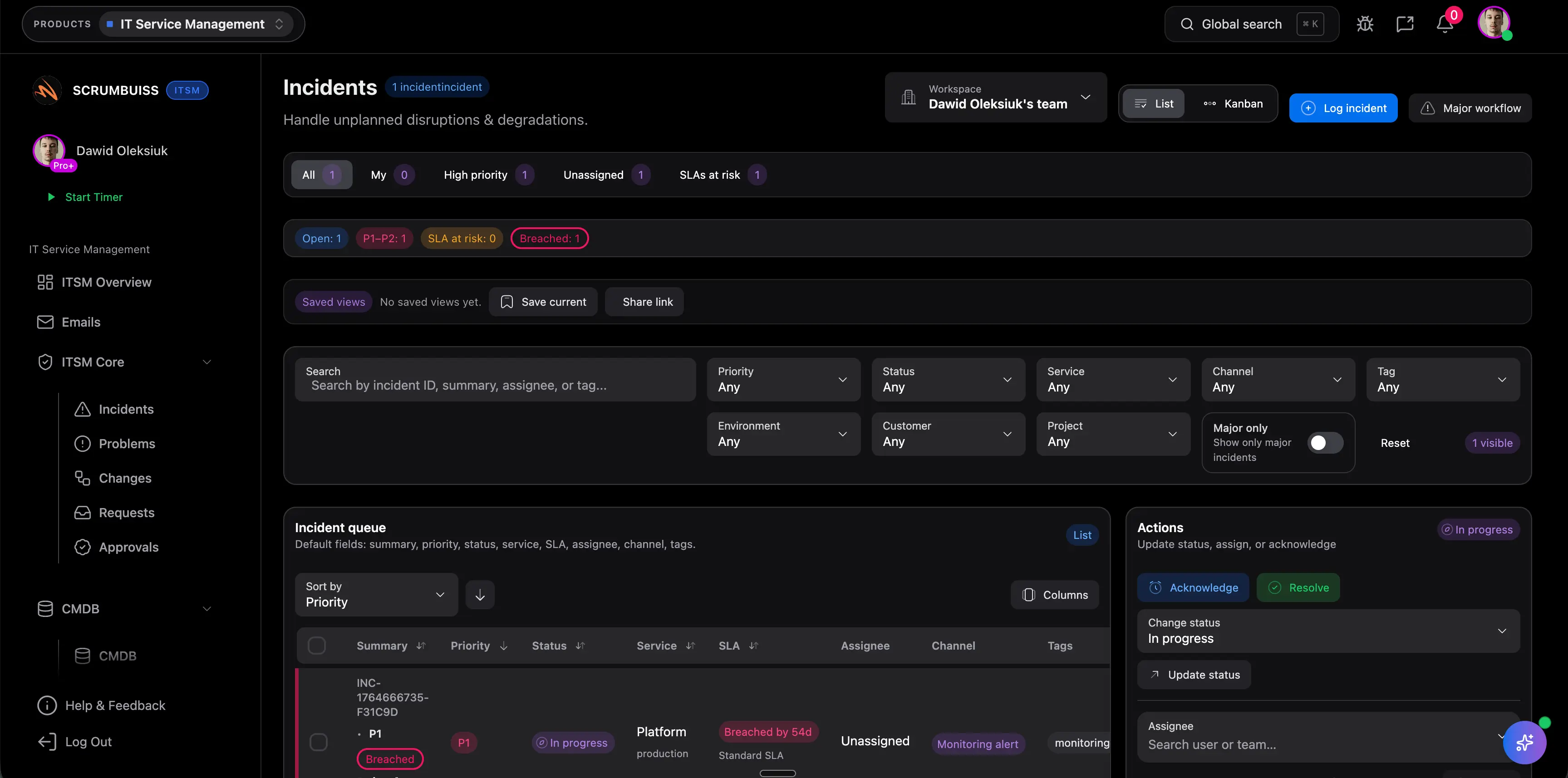
Najpierw oceń problemy, które co tydzień generują tarcie: jak triagowane są incydenty, jak koordynowane są zmiany, jak widoczna pozostaje praca po incydencie i jak informowani są interesariusze. Jeśli historia operacyjna nadal musi być odbudowywana między Slackiem, zgłoszeniami, kalendarzem i dodatkowymi notatkami, narzędzie nie rozwiązuje głównego problemu.
Jaka jest różnica między zarządzaniem incydentami a zarządzaniem zmianami?
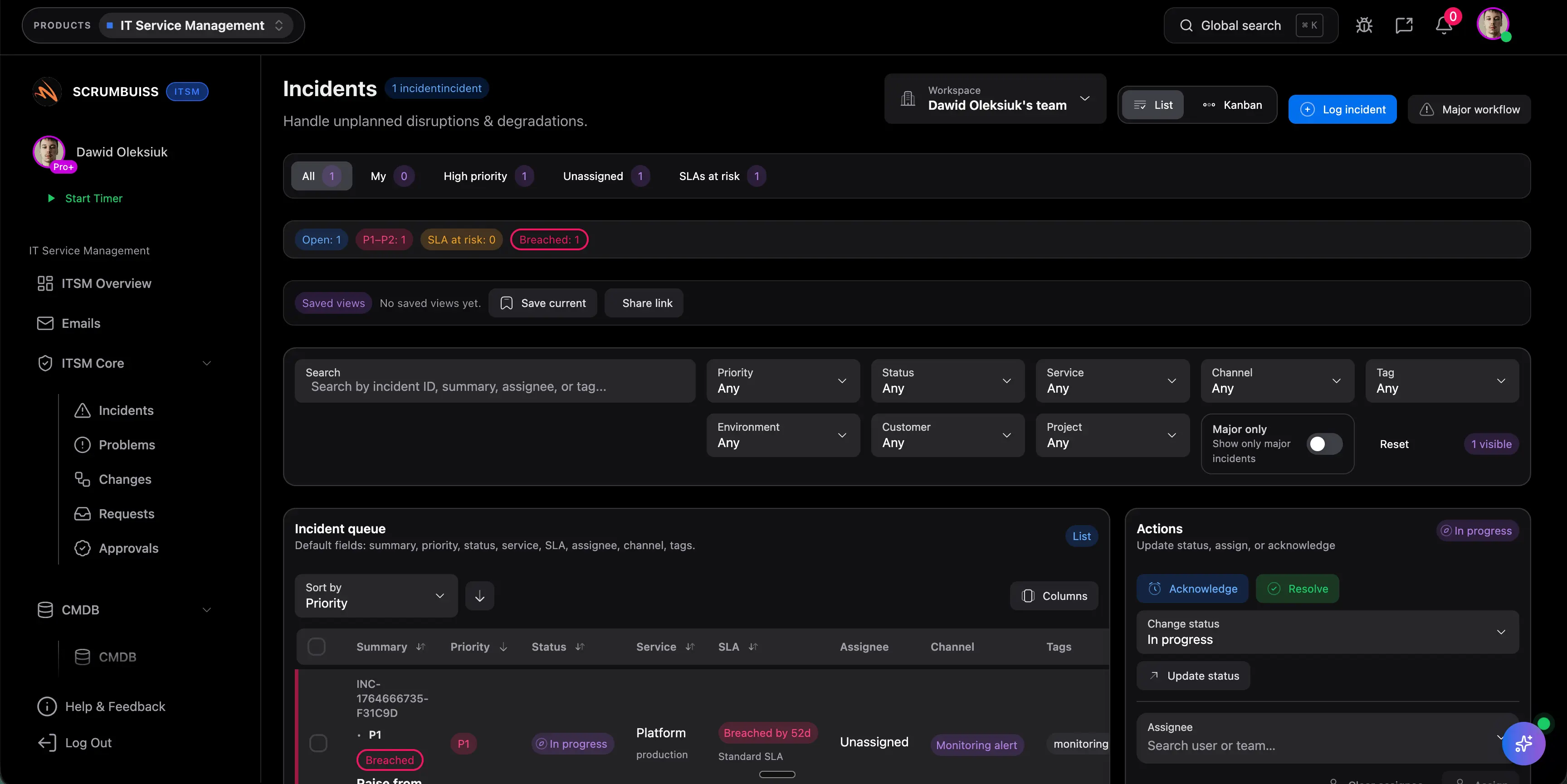
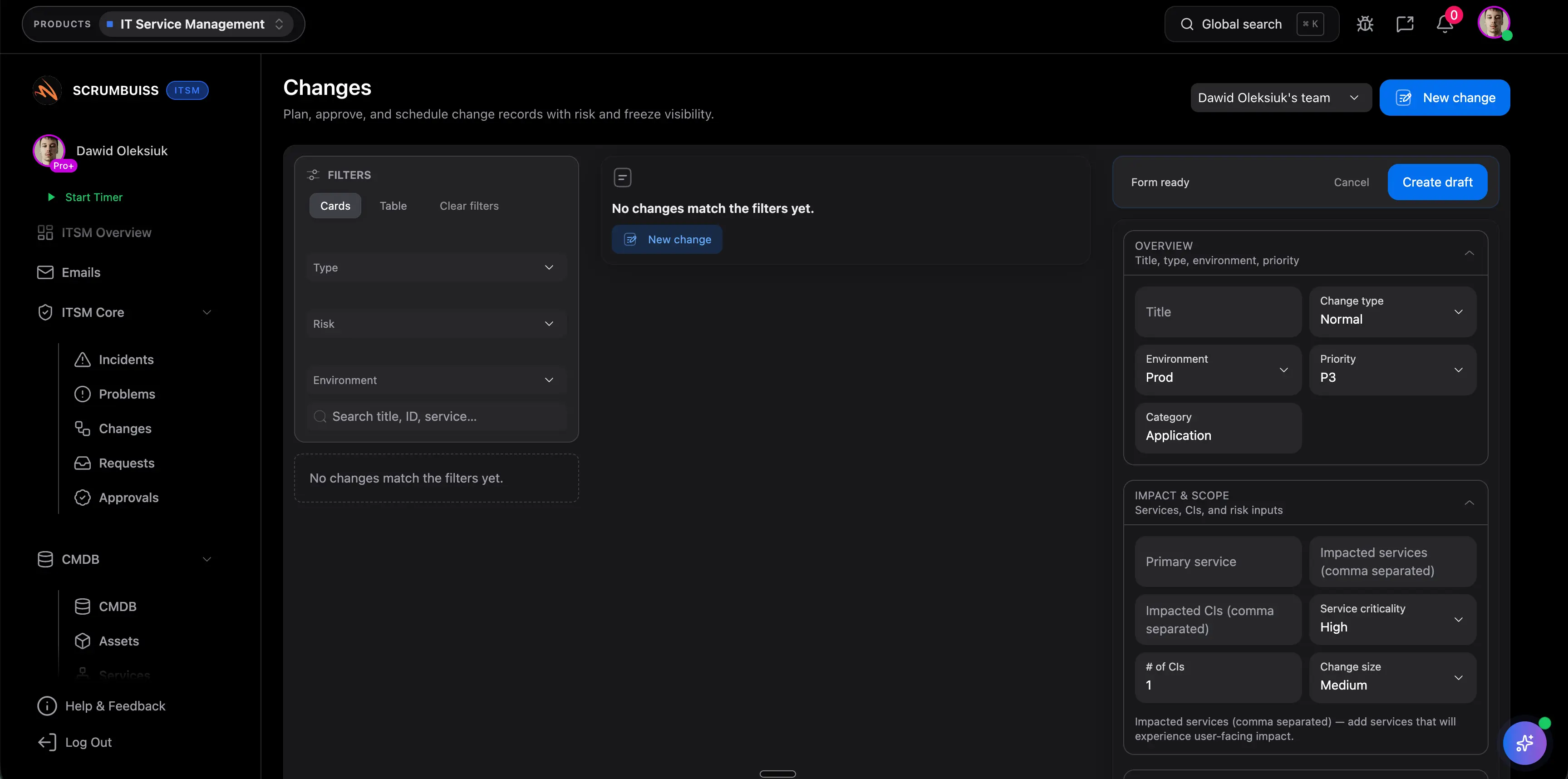
Zarządzanie incydentami pomaga szybko przywrócić stabilność usługi po awarii lub degradacji. Zarządzanie zmianami służy do planowania i komunikowania zmian zanim wygenerują nowe ryzyko. Dobre oprogramowanie ITSM spina oba obszary, bo incydenty i zmiany wpływają na siebie w tym samym rytmie operacyjnym.
Kiedy zespoły zwykle potrzebują ITSM wcześniej, niż im się wydaje?
Wtedy, gdy incydenty przestają być pojedynczymi wyjątkami i zaczynają wpływać na realizację pracy, terminy wdrożeń albo komunikację między zespołami. To często moment wzrostu w software house'ach, zespołach IT operations i środowiskach wsparcia, gdzie luźna lista zgłoszeń przestaje wystarczać.
Jak ocenić pilot ITSM w praktyce?
Najlepiej użyć jednego realnego strumienia incydentów i jednego prawdziwego harmonogramu zmian. Oceń, czy triage jest szybszy, odpowiedzialność czytelniejsza, ręczne raportowanie mniejsze, a działania po incydencie nie znikają po zamknięciu zgłoszenia.
Czym ta strona różni się od strony produktu Scrumbuiss ITSM i strony dla zespołów IT operations?
Ta strona jest przewodnikiem po kategorii: pomaga ocenić, czy w ogóle potrzebujesz oprogramowania ITSM i jaki typ sposobu pracy będzie najlepszy. Strona produktu ITSM służy do oceny dokładnie tego, jak działa konkretny produkt Scrumbuiss. Strona IT operations pokazuje ten sam problem z perspektywy zespołu i jego codziennego modelu operacyjnego.
Czy ITSM może działać w tym samym narzędziu co realizacja pracy i projekty?
Tak, i często ma to sens wtedy, gdy ta sama organizacja koordynuje wdrożenia, incydenty, zmiany i zadania następcze w jednym rytmie pracy. Największa korzyść polega na tym, że od problemu operacyjnego do kolejnej decyzji nie trzeba już odbudowywać kontekstu w innym systemie.
Kiedy cięższa platforma enterprise ITSM będzie lepsza niż Scrumbuiss?
Wtedy, gdy główną potrzebą jest zarządzanie usługami w skali całej organizacji z głęboką administracją, katalogiem usług, procesami opartymi o CMDB i szeroką standaryzacją. Scrumbuiss jest mocniejszy, gdy zespół przede wszystkim chce czytelnego sposobu pracy dla incydentów, zmian i pracy po incydencie.
Dlaczego widoczność zmian jest tak ważna w oprogramowaniu ITSM?
Bo wiele zespołów nie przegrywa na samym zbieraniu zgłoszeń, tylko na kolizjach między zmianami, oknami serwisowymi, wdrożeniami i dostępnością ludzi. Wspólna widoczność zmian ogranicza to ryzyko, bo terminy, wpływ i akceptacje można ocenić zanim praca ruszy.