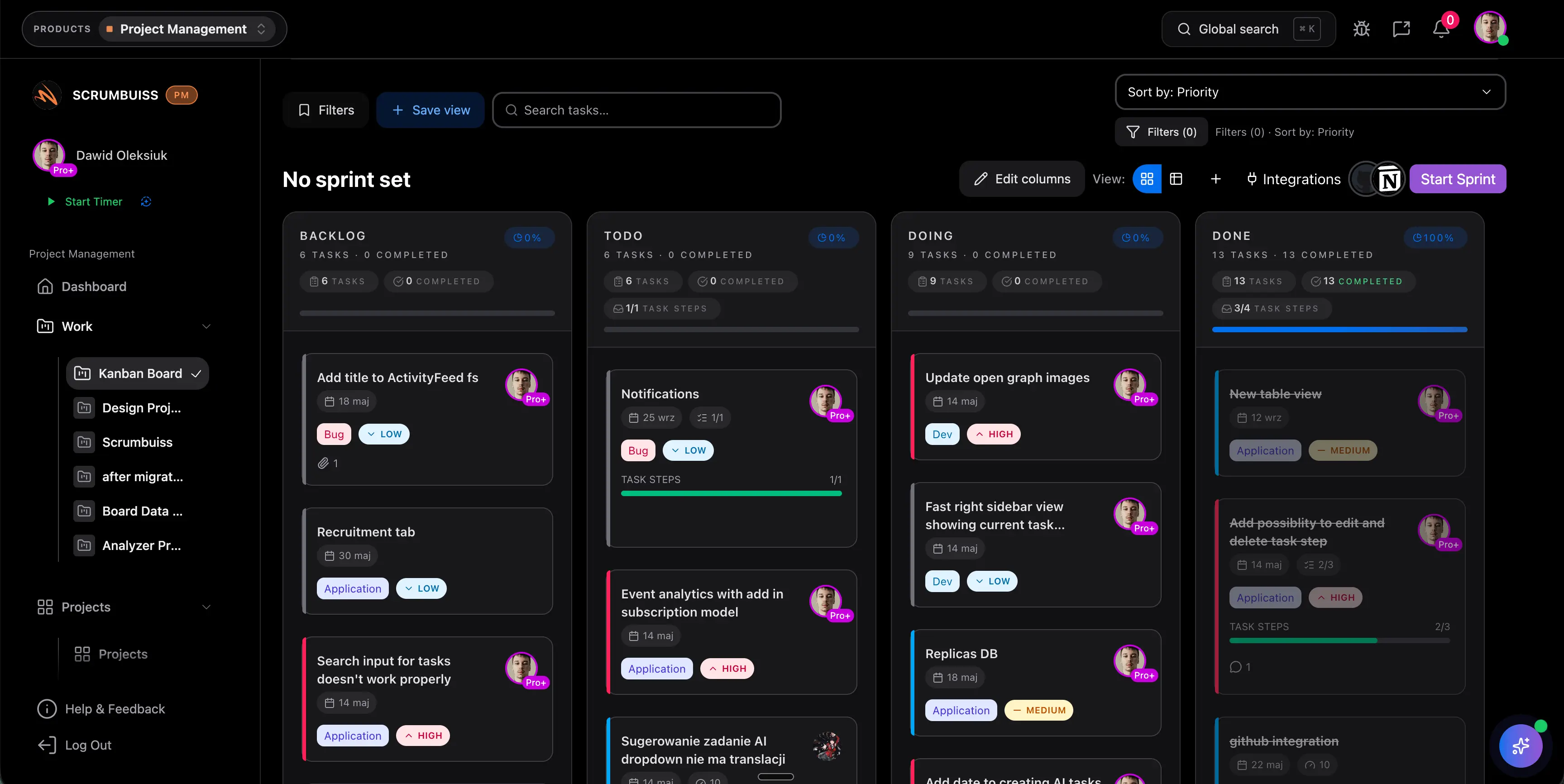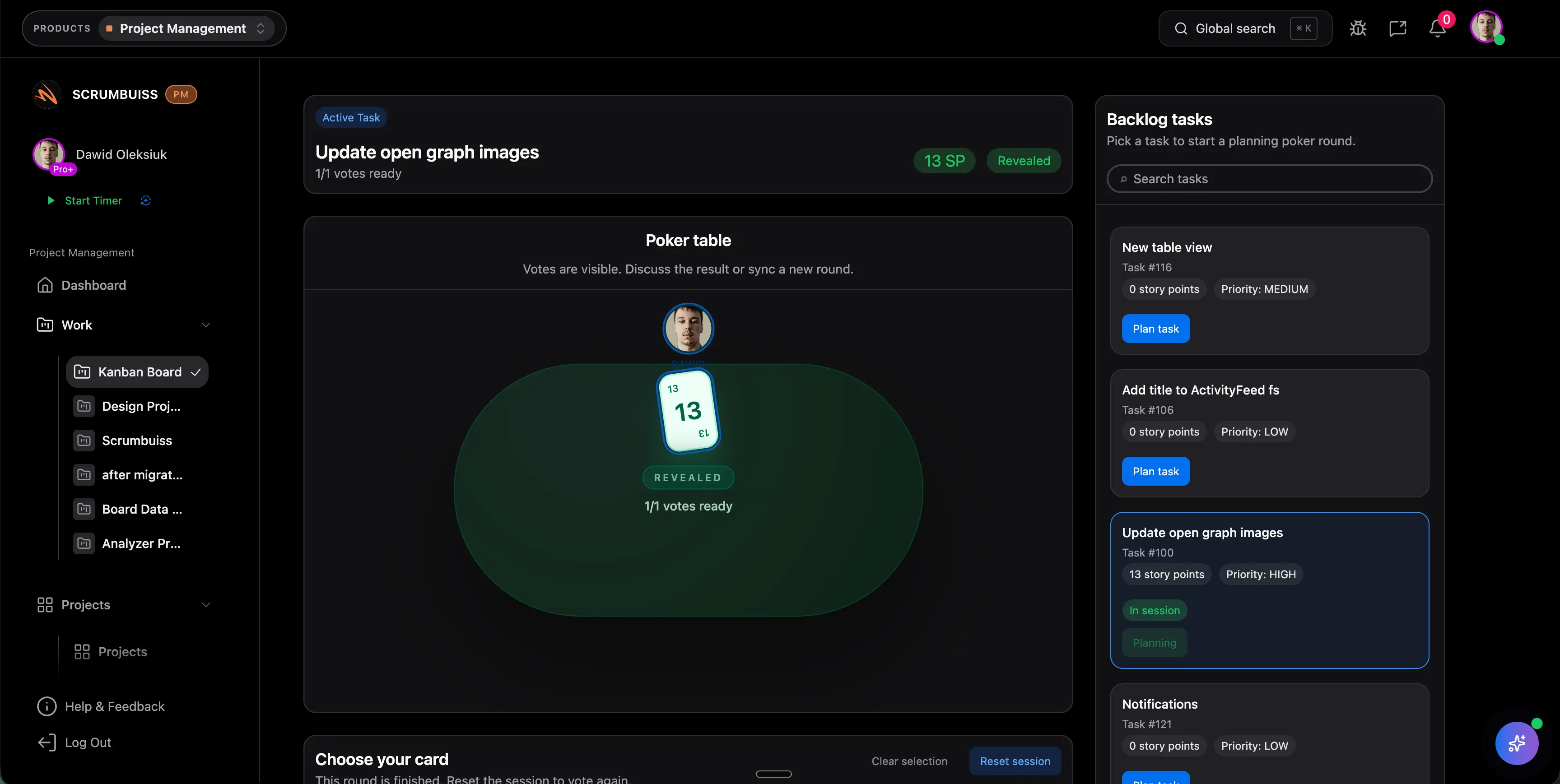
Sprint-Planung und Scope-Abgleich in einen belastbaren Commit übersetzen
Ein Squad plant den nächsten Sprint, priorisiert das Backlog, prüft Abhängigkeiten und gleicht Scope gegen reale Kapazität ab, bevor die Zusage in die Umsetzung geht.
Erkenne Delivery-Risiken früh mit Trends, Empfehlungen und Automations-Triggern.
Workflows gesucht? Entdecke Anwendungsfälle oder stöbere in Funktionen .
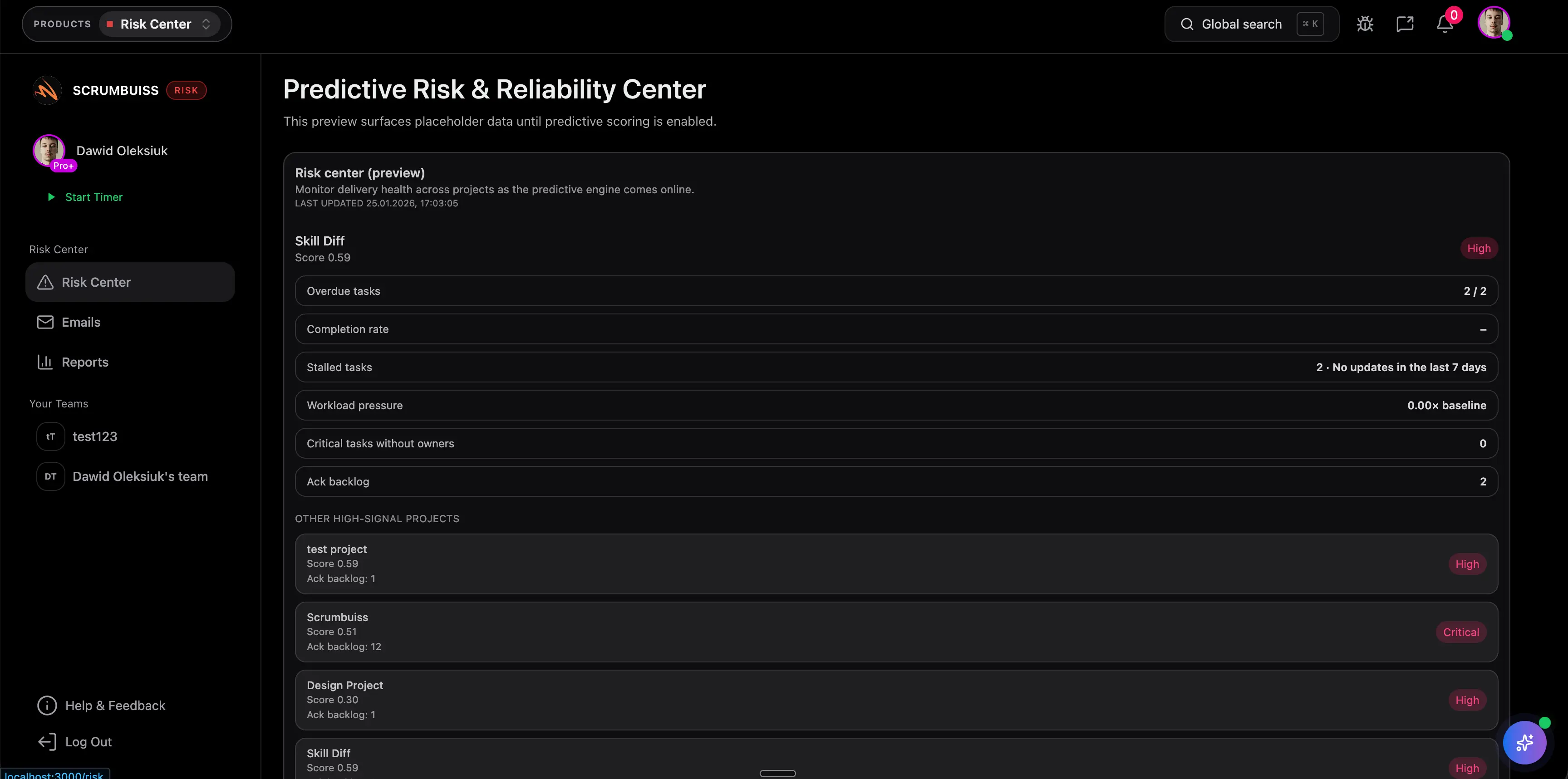
Entdecke passende Feature-Seiten für mehr Details.
Nutze diesen Rollout als praktischen Startpunkt für deinen ersten Workspace.
Ein Squad plant den nächsten Sprint, priorisiert das Backlog, prüft Abhängigkeiten und gleicht Scope gegen reale Kapazität ab, bevor die Zusage in die Umsetzung geht.
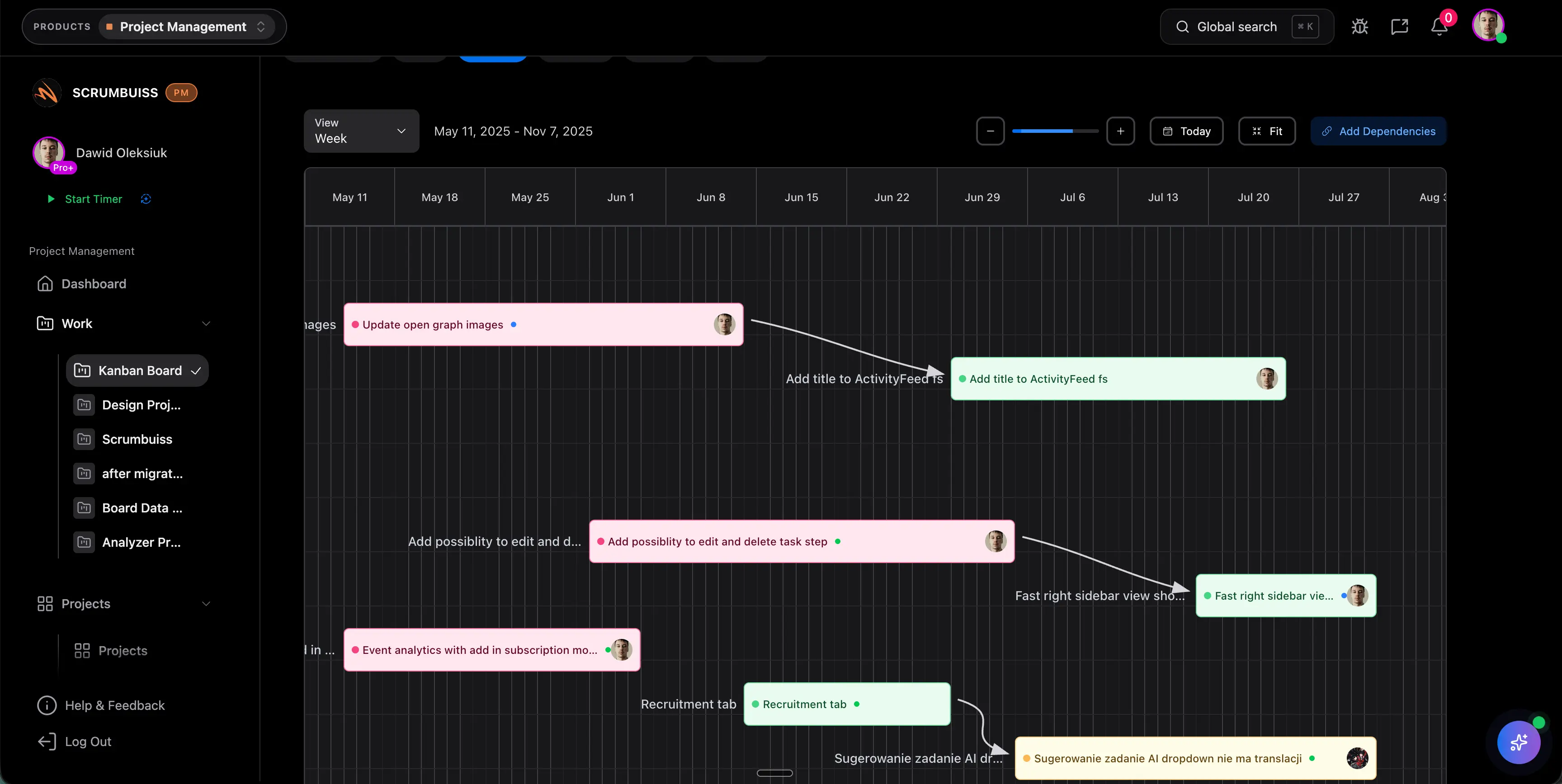
Während der Sprint läuft, bleiben Blocker, Repo-nahe Delivery-Signale, Owner-Wechsel und Abhängigkeiten nah genug an der Arbeit, damit die Planung nicht in Chats und Neben-Listen zerfällt.
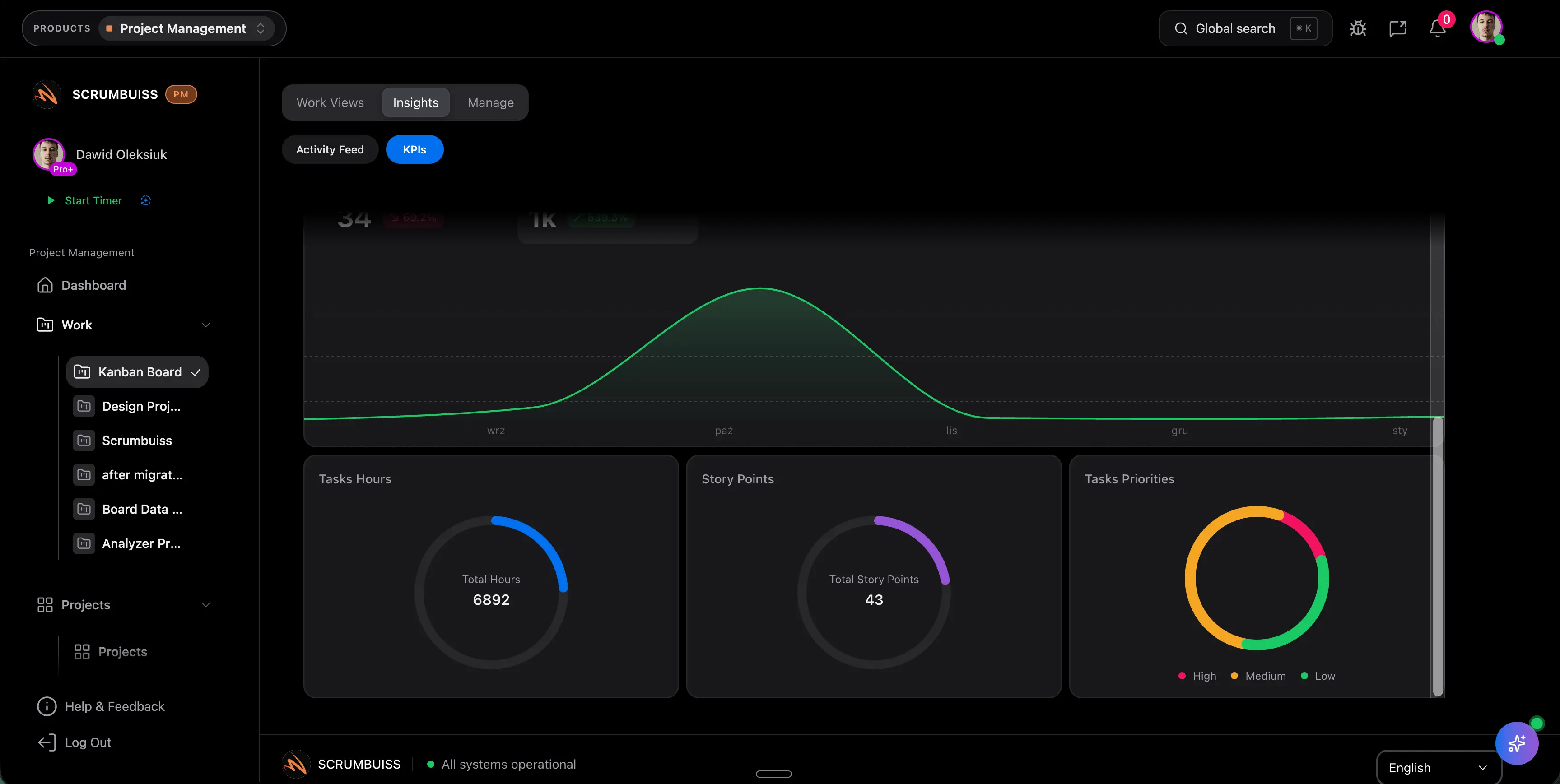
Zum Weekly Review oder Release-Checkpoint sollte der Squad Fortschritt, Risiken und nächste Schritte aus dem laufenden Workflow erklären können, ohne den Sprint erst aus mehreren Quellen neu zusammenzusetzen.
Das sind typische operative Verbesserungen, auf die Teams nach dem Rollout hinarbeiten.
Wenn Sprint-Planung, Delivery-Signale und Reporting enger zusammenbleiben, verbringen Leads weniger Zeit damit, den Fortschritt aus Board, Repo und Chat nachzuerzählen.
Illustratives Beispiel: Spare 1 bis 2 Stunden pro Woche je Engineering- oder Delivery-Lead, wenn Weekly Updates nicht mehr aus mehreren Systemen zusammengesetzt werden müssen.
Sichtbare Abhängigkeiten und Auslastung helfen Teams, Blocker und Überlast vor dem eigentlichen Release-Druck zu erkennen.
Illustratives Beispiel: Vermeide späte Umplanungen und spare 1 bis 2 Stunden pro Squad und Sprint, wenn kritische Abhängigkeiten vor dem Review statt nach dem Verzug auffallen.
Wenn Planning, Kapazität und Delivery-Kontext nicht auseinanderfallen, werden Commitments realistischer und Reviews produktiver.
Illustratives Beispiel: Gewinne 30 bis 45 Minuten pro Sprint-Planung zurück und reduziere stillen Scope-Drift, wenn Estimation und Kapazitätscheck im selben Workflow bleiben.
Starte schlank und füge mehr Struktur hinzu, sobald der Workflow läuft.
Sieh, wie Teams dieses Produkt in realen Szenarien einsetzen.
Kopiere und passe diese Vorlagen an, um deinen Workflow zu starten.
Lade eine kostenlose Sprintplanungs-Vorlage mit Sprintziel, Umfang, Kapazität, Abhängigkeiten und Checkliste für Excel oder Google Sheets herunter.
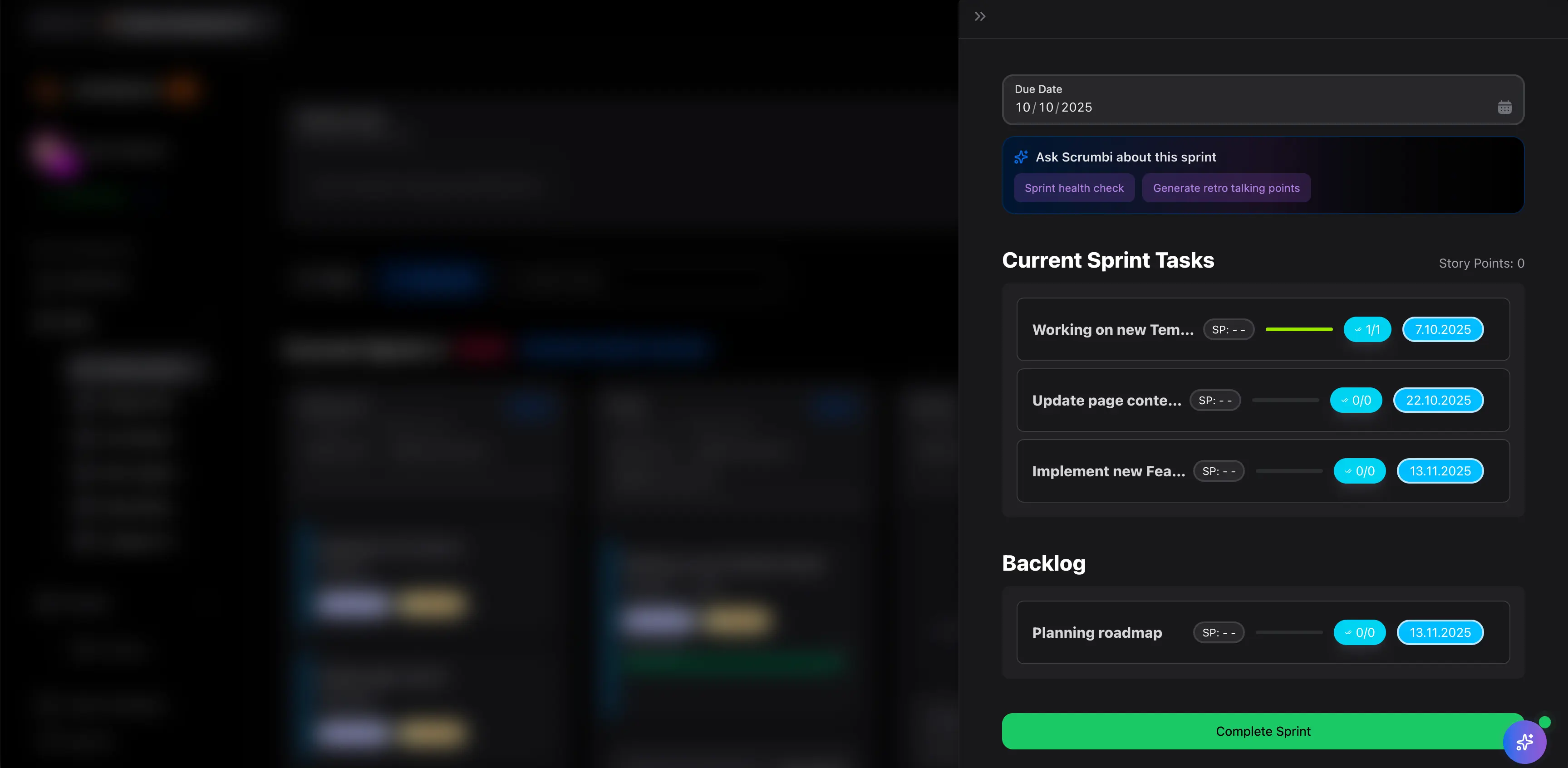
Lade eine kostenlose Projektsteckbrief-Vorlage mit ausgefuelltem Beispiel, One-Pager-Struktur und Kickoff-Checkliste herunter, um Ziele, Scope, Stakeholder, Kommunikation und Freigaben sauber festzuhalten.
Lade eine kostenlose Risikoregister-Vorlage als CSV mit ausgefülltem Beispiel, 1-bis-5-Bewertung, klaren Verantwortlichkeiten, Frühindikatoren und wöchentlicher Prüflogik herunter.
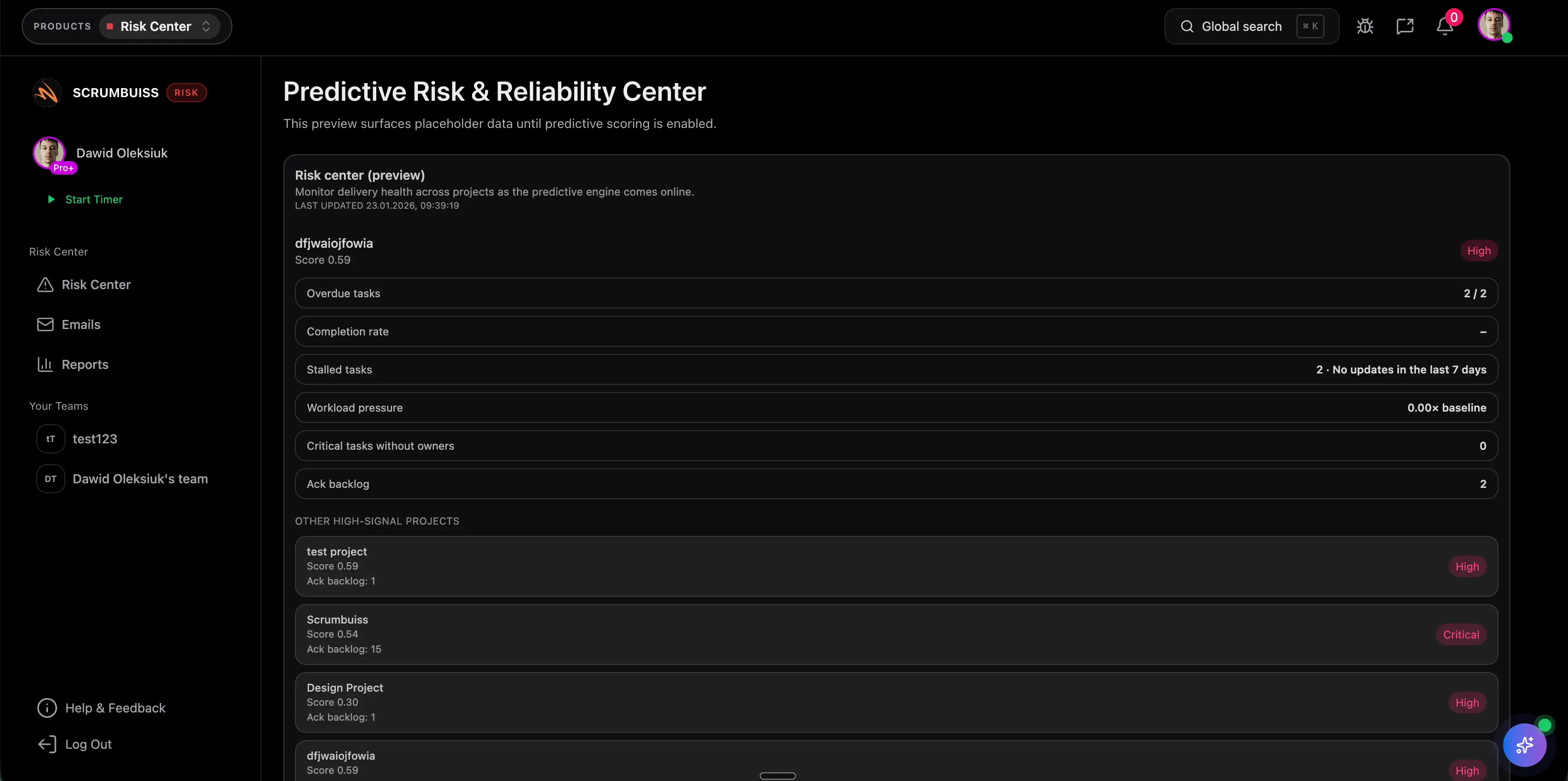
Nein — es ergänzt es. Du brauchst weiterhin klare Ownership und Prozesse, und das Risk Center hilft, Signale früher sichtbar zu machen.
Ja. Nutze Automations-Trigger, um Stakeholder zu benachrichtigen oder Follow-up-Tasks zu erstellen, wenn Schwellenwerte überschritten werden.
Bewertungsnotizen
Eine Bewertung von Risk-Center-Workflows funktioniert am besten, wenn sie an einem realen Delivery-Pfad haengt. Die folgenden Notizen helfen Teams, Scrumbuiss mit der Art zu vergleichen, wie sie heute Arbeit planen, uebergeben, berichten und reviewen.
Wenn Teams Risk-Center-Workflows pruefen, ist die wichtigste Frage, ob der naechste Owner Scope, Termine, Blocker, Dateien und Freigaben sieht, ohne die Geschichte aus Chatverlaeufen oder alten Meetingnotizen neu aufzubauen. So bleibt die Bewertung an echter Arbeit orientiert statt an einer generischen Feature-Liste. Das ist die Baseline fuer den ersten Pilot.
Ein praxisnaher Pilot fuer Risk-Center-Workflows sollte operativer Kontext enthalten, weil taegliche Arbeit, Status, Delivery-Sicherheit und Zusagen an Kunden zusammenbleiben, statt zwischen Board, Tabelle und Reporting-Deck auseinanderzufallen. Dadurch wird auch die Demo leichter bewertbar, weil das Team den alten und neuen Ablauf Schritt fuer Schritt vergleichen kann. Das ist die Baseline fuer den ersten Pilot.
Das staerkste Signal fuer Risk-Center-Workflows ist kein weiterer statischer Screen, sondern der Nachweis, dass das Setup so einfach bleibt, dass Account Leads, Projektmanager, Contributors und Stakeholder es nach der ersten Woche weiter nutzen. Fehlt dieser Nachweis, entsteht oft nur eine weitere Reporting-Schicht statt weniger Koordinationsarbeit. Das ist die Baseline fuer den ersten Pilot.
Vor der Tool-Auswahl fuer Risk-Center-Workflows sollte dokumentiert werden, wie der heutige Prozess Reporting-Qualitaet behandelt und ob Fuehrungskraefte echte Delivery-Risiken von normalem Aktivitaetsrauschen unterscheiden koennen, weil Schaetzungen, Owner, Termine, Auslastung und Kommentare gemeinsam betrachtet werden. Scrumbuiss haelt diese Signale nah an der Arbeit, damit das operative Bild lesbar bleibt. Das ist die Baseline fuer den ersten Pilot.
Wenn Teams Risk-Center-Workflows pruefen, ist die wichtigste Frage, ob Kunden oder externe Stakeholder einen lesbaren Status erhalten, ohne in jedes interne operative Detail eingeladen zu werden. So bleibt die Bewertung an echter Arbeit orientiert statt an einer generischen Feature-Liste. Das ist die Baseline fuer den ersten Pilot.
Ein praxisnaher Pilot fuer Risk-Center-Workflows sollte strukturierter Intake enthalten, weil neue Arbeit mit genug Kontext startet, um sie zu routen, zu priorisieren und ohne weitere Klaerung in Delivery zu bringen. Dadurch wird auch die Demo leichter bewertbar, weil das Team den alten und neuen Ablauf Schritt fuer Schritt vergleichen kann. Das ist die Baseline fuer den ersten Pilot.
Das staerkste Signal fuer Risk-Center-Workflows ist kein weiterer statischer Screen, sondern der Nachweis, dass Briefs, Anhaenge, Kommentare und Freigaben nah an den Aufgaben und Meilensteinen bleiben, die sie beeinflussen. Fehlt dieser Nachweis, entsteht oft nur eine weitere Reporting-Schicht statt weniger Koordinationsarbeit. Das ist die Baseline fuer den ersten Pilot.
Vor der Tool-Auswahl fuer Risk-Center-Workflows sollte dokumentiert werden, wie der heutige Prozess Kapazitaetsplanung behandelt und ob das Team frueh sieht, ob Arbeit durch Personen, Abhaengigkeiten, Reviews oder ungeplante Incidents blockiert ist. Scrumbuiss haelt diese Signale nah an der Arbeit, damit das operative Bild lesbar bleibt. Das ist die Baseline fuer den ersten Pilot.
Wenn Teams Risk-Center-Workflows pruefen, ist die wichtigste Frage, ob der erste Rollout mit einem echten Workflow beginnt, das Betriebsmodell beweist und danach wachsen kann, ohne alles neu aufzusetzen. So bleibt die Bewertung an echter Arbeit orientiert statt an einer generischen Feature-Liste. Das ist die Baseline fuer den ersten Pilot.
Ein praxisnaher Pilot fuer Risk-Center-Workflows sollte Governance enthalten, weil Berechtigungen, Ownership, Statusregeln und Eskalationswege fuer Management, Contributors, Kunden und Procurement klar genug sind. Dadurch wird auch die Demo leichter bewertbar, weil das Team den alten und neuen Ablauf Schritt fuer Schritt vergleichen kann. Das ist die Baseline fuer den ersten Pilot.
Das staerkste Signal fuer Risk-Center-Workflows ist kein weiterer statischer Screen, sondern der Nachweis, dass das Team vereinbart, welche Signale zaehlen, etwa Cycle Time, Estimate-Abweichung, offene Risiken, ueberfaellige Reviews, blockierte Arbeit und Handoff-Rework. Fehlt dieser Nachweis, entsteht oft nur eine weitere Reporting-Schicht statt weniger Koordinationsarbeit. Das ist die Baseline fuer den ersten Pilot.
Vor der Tool-Auswahl fuer Risk-Center-Workflows sollte dokumentiert werden, wie der heutige Prozess Automatisierungs-Fit behandelt und ob Reminder, Routing-Regeln und Follow-up-Hinweise wiederholte Koordination reduzieren, ohne Verantwortung zu verstecken. Scrumbuiss haelt diese Signale nah an der Arbeit, damit das operative Bild lesbar bleibt. Das ist die Baseline fuer den ersten Pilot.
Wenn Teams Risk-Center-Workflows pruefen, ist die wichtigste Frage, ob verbundene Tools ihre Source-of-Truth-Rolle behalten, waehrend Scrumbuiss Projekterzaehlung, naechste Aktion und Stakeholder-Update lesbar haelt. So bleibt die Bewertung an echter Arbeit orientiert statt an einer generischen Feature-Liste. Das ist die Baseline fuer den ersten Pilot.
Ein praxisnaher Pilot fuer Risk-Center-Workflows sollte Security Review enthalten, weil Vendor Checks, Rollenrechte, externes Teilen und Procurement-Fragen so frueh geklaert werden, dass sie den Pilot nicht ausbremsen. Dadurch wird auch die Demo leichter bewertbar, weil das Team den alten und neuen Ablauf Schritt fuer Schritt vergleichen kann. Das ist die Baseline fuer den ersten Pilot.
Das staerkste Signal fuer Risk-Center-Workflows ist kein weiterer statischer Screen, sondern der Nachweis, dass die Seite hilft, zuerst den richtigen Workflow zu testen, passende Evidenz zu sammeln und angrenzende Prozesse vor einem breiteren Rollout zu pruefen. Fehlt dieser Nachweis, entsteht oft nur eine weitere Reporting-Schicht statt weniger Koordinationsarbeit. Das ist die Baseline fuer den ersten Pilot.
Vor der Tool-Auswahl fuer Risk-Center-Workflows sollte dokumentiert werden, wie der heutige Prozess langfristige Wartbarkeit behandelt und ob das Betriebsmodell lesbar bleibt, wenn mehr Projekte, mehr Kunden, mehr Abhaengigkeiten oder mehr Reporting-Ebenen hinzukommen. Scrumbuiss haelt diese Signale nah an der Arbeit, damit das operative Bild lesbar bleibt. Das ist die Baseline fuer den ersten Pilot.
Wenn Teams Risk-Center-Workflows pruefen, ist die wichtigste Frage, ob der naechste Owner Scope, Termine, Blocker, Dateien und Freigaben sieht, ohne die Geschichte aus Chatverlaeufen oder alten Meetingnotizen neu aufzubauen. So bleibt die Bewertung an echter Arbeit orientiert statt an einer generischen Feature-Liste. Dieser Punkt sollte erneut geprueft werden, wenn mehr Teams, Gaeste oder kundensichtbare Updates dazukommen.
Ein praxisnaher Pilot fuer Risk-Center-Workflows sollte operativer Kontext enthalten, weil taegliche Arbeit, Status, Delivery-Sicherheit und Zusagen an Kunden zusammenbleiben, statt zwischen Board, Tabelle und Reporting-Deck auseinanderzufallen. Dadurch wird auch die Demo leichter bewertbar, weil das Team den alten und neuen Ablauf Schritt fuer Schritt vergleichen kann. Dieser Punkt sollte erneut geprueft werden, wenn mehr Teams, Gaeste oder kundensichtbare Updates dazukommen.
Das staerkste Signal fuer Risk-Center-Workflows ist kein weiterer statischer Screen, sondern der Nachweis, dass das Setup so einfach bleibt, dass Account Leads, Projektmanager, Contributors und Stakeholder es nach der ersten Woche weiter nutzen. Fehlt dieser Nachweis, entsteht oft nur eine weitere Reporting-Schicht statt weniger Koordinationsarbeit. Dieser Punkt sollte erneut geprueft werden, wenn mehr Teams, Gaeste oder kundensichtbare Updates dazukommen.
Vor der Tool-Auswahl fuer Risk-Center-Workflows sollte dokumentiert werden, wie der heutige Prozess Reporting-Qualitaet behandelt und ob Fuehrungskraefte echte Delivery-Risiken von normalem Aktivitaetsrauschen unterscheiden koennen, weil Schaetzungen, Owner, Termine, Auslastung und Kommentare gemeinsam betrachtet werden. Scrumbuiss haelt diese Signale nah an der Arbeit, damit das operative Bild lesbar bleibt. Dieser Punkt sollte erneut geprueft werden, wenn mehr Teams, Gaeste oder kundensichtbare Updates dazukommen.