Diese Fragen müssen Teams meist beantworten, bevor ITSM Teil des echten Betriebs-Workflows wird.
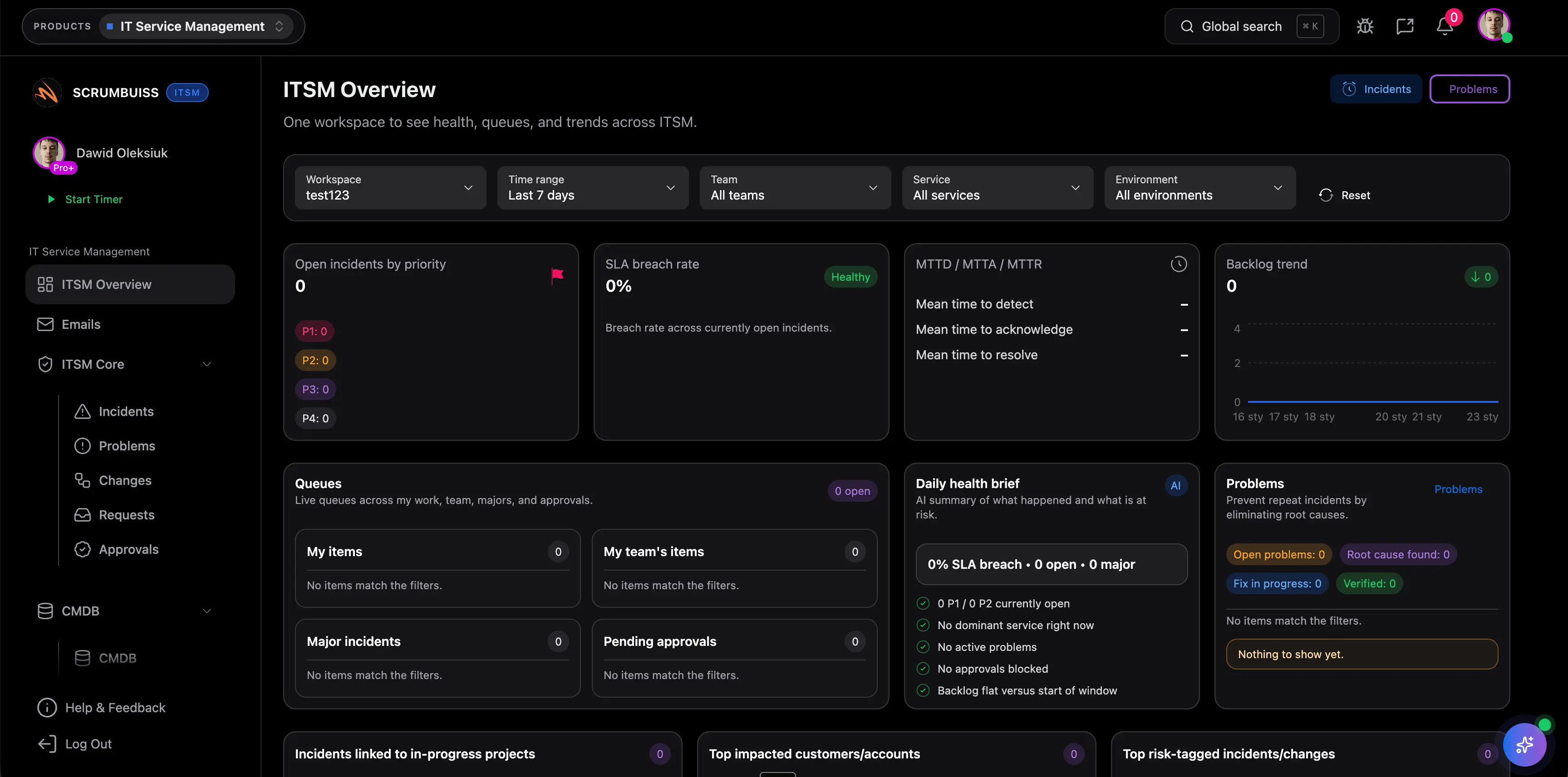
Worauf sollten Teams bei ITSM Software zuerst achten?
Startet mit den Fragen, die jede Woche Reibung erzeugen: Wie werden Incidents triagiert, wie werden Changes abgestimmt, wie bleibt Folgearbeit sichtbar und wie werden Stakeholder informiert? Wenn der Betriebsablauf weiterhin auf Chat, Tabellen oder manuell geschriebenen Status-Updates beruht, löst die Software das eigentliche Problem noch nicht.
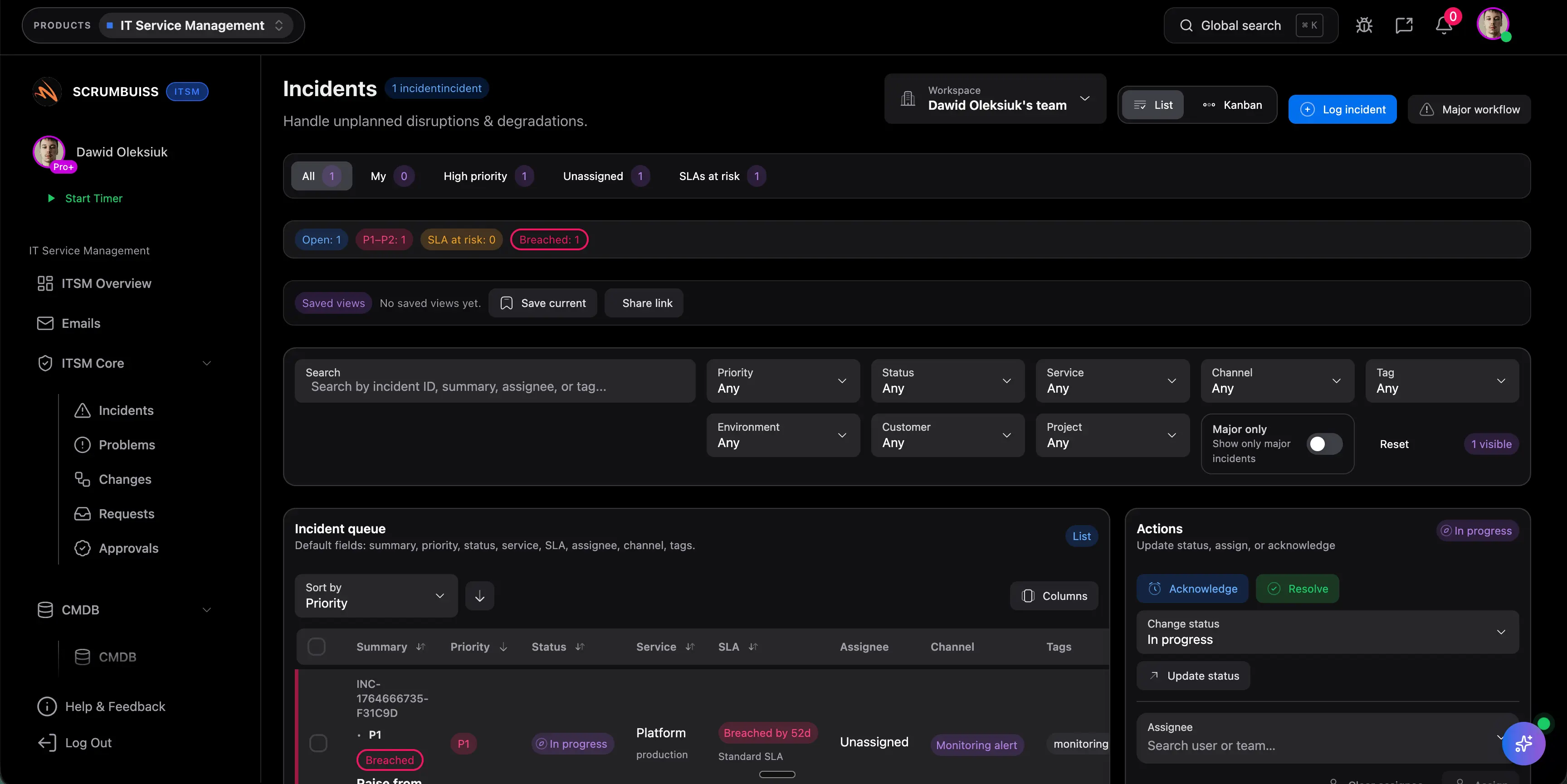
Was ist der Unterschied zwischen Incident Management und Change Management?
Incident Management hilft, Services nach Störungen oder Degradationen schnell wieder stabil zu bekommen. Change Management plant und kommuniziert Änderungen, bevor neue Risiken entstehen. Gute ITSM Software verbindet beides, weil Changes und Incidents im selben Betriebsrhythmus aufeinander wirken.
Wann brauchen Teams meist früher ITSM Software als gedacht?
Sobald Incidents nicht mehr isolierte Einzelfälle sind, sondern Delivery-Pläne, Releases oder bereichsübergreifende Kommunikation beeinflussen. Das passiert häufig in wachsenden Software-Organisationen, IT-Operations-Teams und Support-lastigen Umgebungen, in denen eine lose Ticketliste nicht mehr reicht.
Wie sollte ein ITSM Pilot bewertet werden?
Mit einem echten Incident-Strom und einem echten Change-Zeitplan. Bewertet, ob Triage schneller wird, Ownership klarer bleibt, manuelle Reporting-Arbeit sinkt und Folgearbeit nicht nach dem akuten Vorfall wieder im Nichts verschwindet.
Kann ITSM im selben Tool wie Delivery und Projektarbeit laufen?
Ja. Das ist besonders sinnvoll, wenn dieselbe Organisation Releases, Incidents, Changes und Backlog-Folgearbeit gemeinsam koordinieren muss. Der Vorteil ist, dass der Weg vom operativen Problem zur nächsten Delivery-Maßnahme ohne Kontextverlust möglich bleibt.
Wann passt eine schwerere Enterprise-ITSM-Plattform besser als Scrumbuiss?
Wenn der Kernbedarf in Enterprise-weitem Service Management mit tiefer Administration, Servicekatalogen, CMDB-lastigen Prozessen oder breiter organisatorischer Standardisierung liegt. Scrumbuiss ist stärker, wenn Teams vor allem einen lesbaren Workflow für Incident Management, Change Management und Folgearbeit wollen.
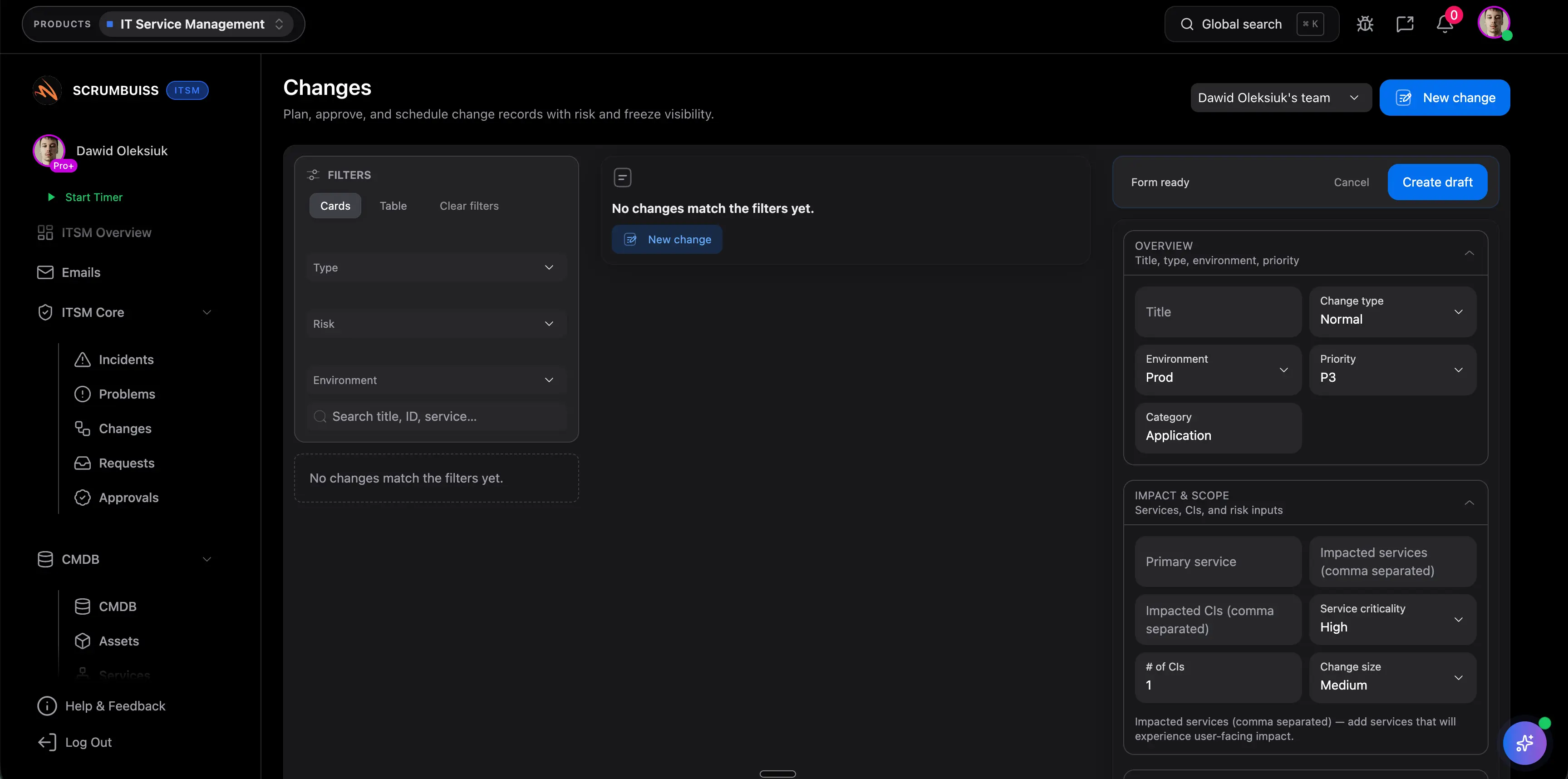
Warum ist Change-Sichtbarkeit in ITSM Software so wichtig?
Weil viele Teams nicht an fehlenden Tickets scheitern, sondern an kollidierenden Changes, Wartungsfenstern, Releases und Personalengpässen. Gemeinsame Change-Sichtbarkeit reduziert dieses Risiko, weil Timing, Impact und Freigaben vor dem Start der Arbeit überprüfbar werden.