These are the buying and rollout questions teams usually need answered before
ITSM becomes part of the real operating workflow.
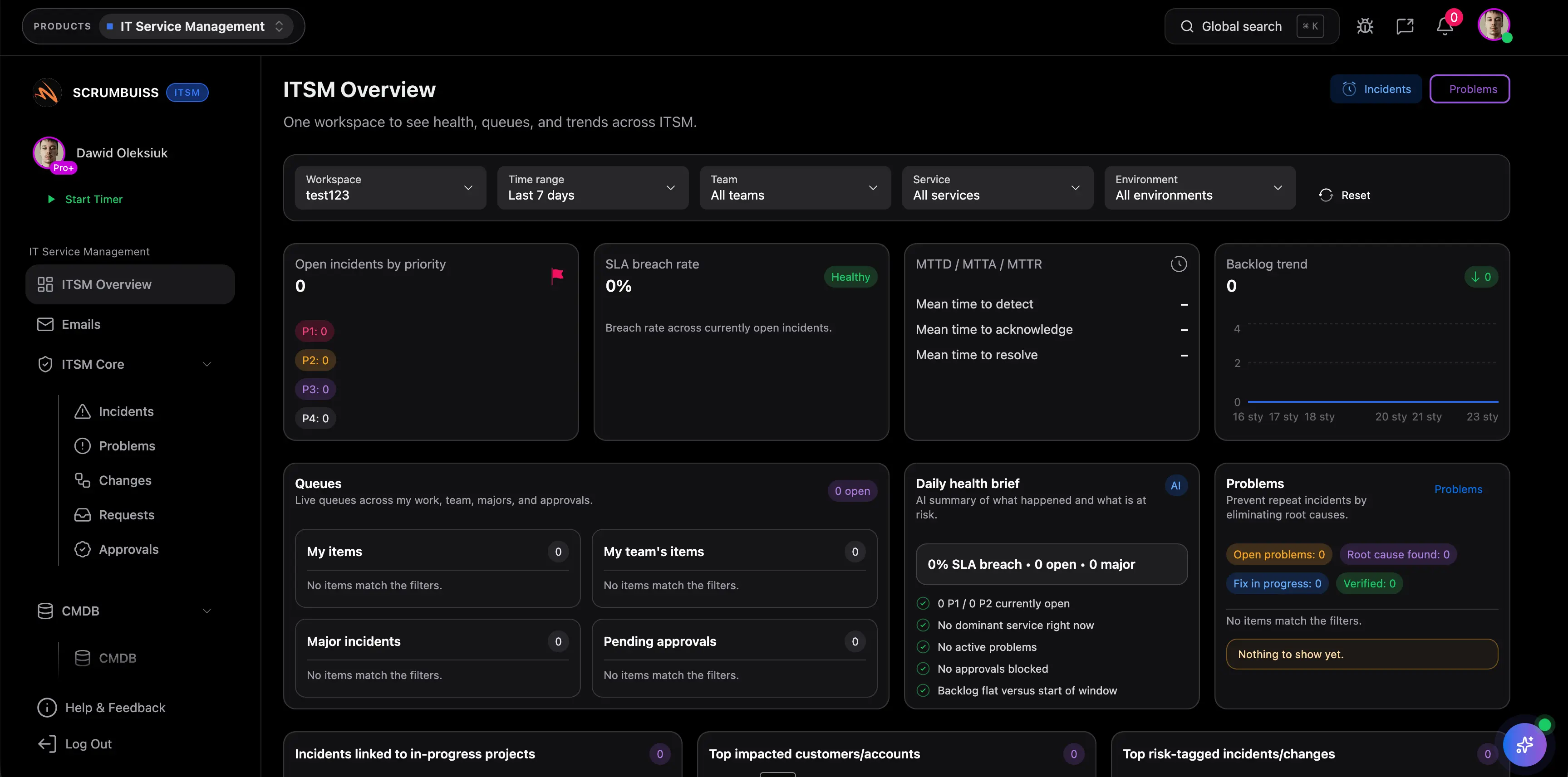
What should teams look for in ITSM software first?
Start with the operating questions that create weekly friction: how incidents are triaged, how change windows are coordinated, how recurring issues are tracked after the initial fix, and how stakeholders stay informed. If the workflow still depends on chat threads, spreadsheets, or manual status translation, the tool is not solving the real problem yet.
What is the difference between incident management and change management software?
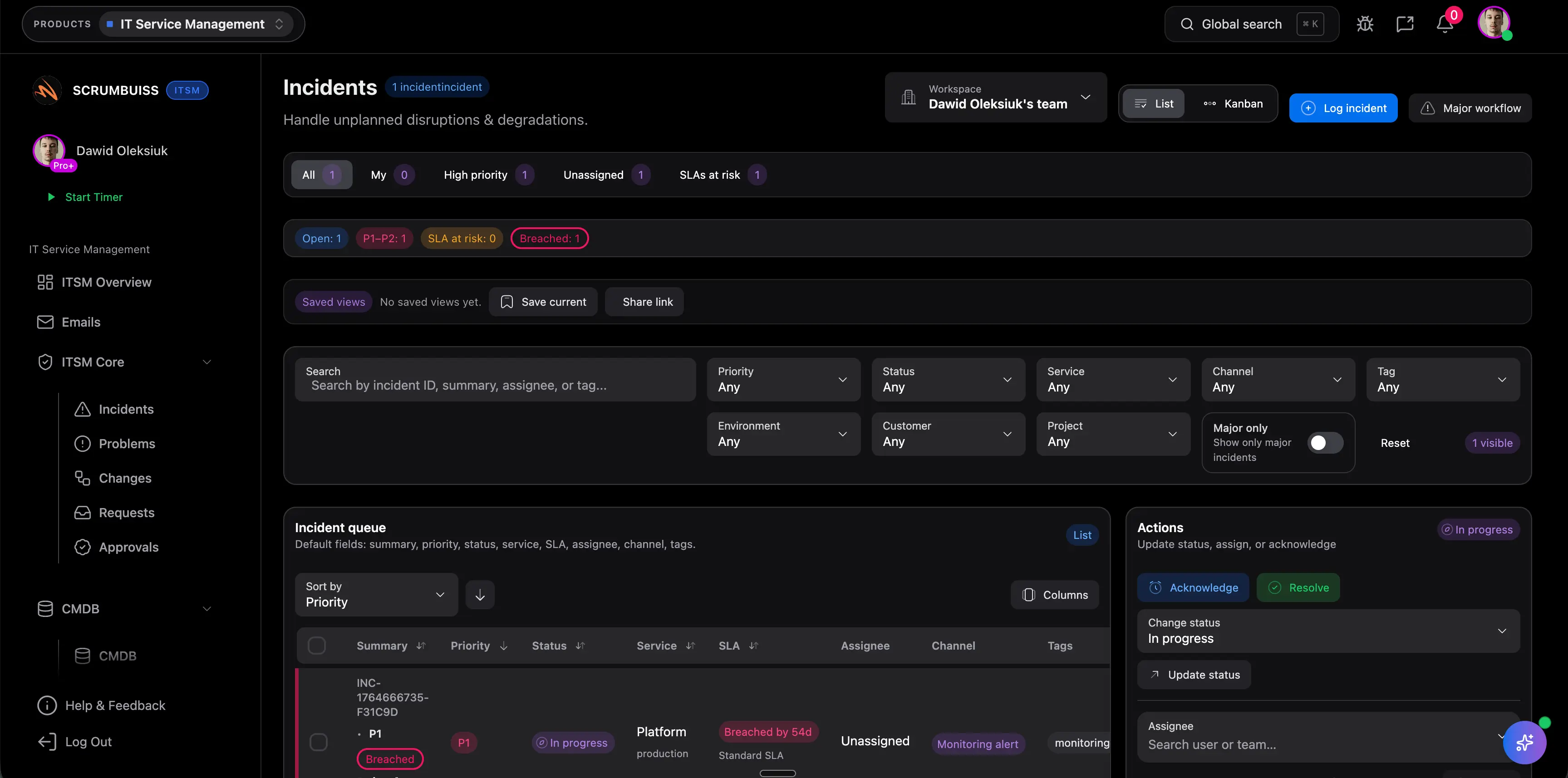
Incident management focuses on restoring service quickly when something breaks or degrades. Change management focuses on planning and communicating operational changes before they create new disruption. Strong ITSM software usually supports both because incidents and changes influence each other in the same operating rhythm.
Who usually needs ITSM software before they think they do?
Teams usually need it once incidents stop being isolated events and start affecting delivery plans, release timing, or cross-team communication. That often happens in growing software organizations, IT operations teams, and support-heavy environments where operational work is no longer manageable as a loose ticket queue.
How should a team evaluate an ITSM pilot?
Use one real incident stream and one real change schedule. Measure whether the tool makes triage faster, keeps ownership clearer, reduces manual reporting, and helps the team carry follow-up work into the next review instead of forgetting it once the immediate problem is closed.
Can ITSM live in the same tool as delivery and project work?
Yes, and that is often useful when the same organization coordinates releases, incidents, changes, and backlog follow-up together. The advantage is that the team can move from an operational issue to the next delivery action without rebuilding the context elsewhere.
When is a heavier enterprise ITSM platform a better fit than Scrumbuiss?
A larger platform can make more sense when the core requirement is enterprise-scale service management with deep administration, service catalogs, CMDB-heavy workflows, or broader organizational standardization. Scrumbuiss is stronger when the team wants a more readable operating workflow for incident coordination, change visibility, and follow-up work.
Why does change scheduling matter so much in IT operations software?
Because many teams do not fail on ticket capture. They fail when planned changes collide with releases, maintenance windows, staffing limits, or dependent systems. Shared change visibility reduces that risk by making timing and impact easier to review before the work starts.