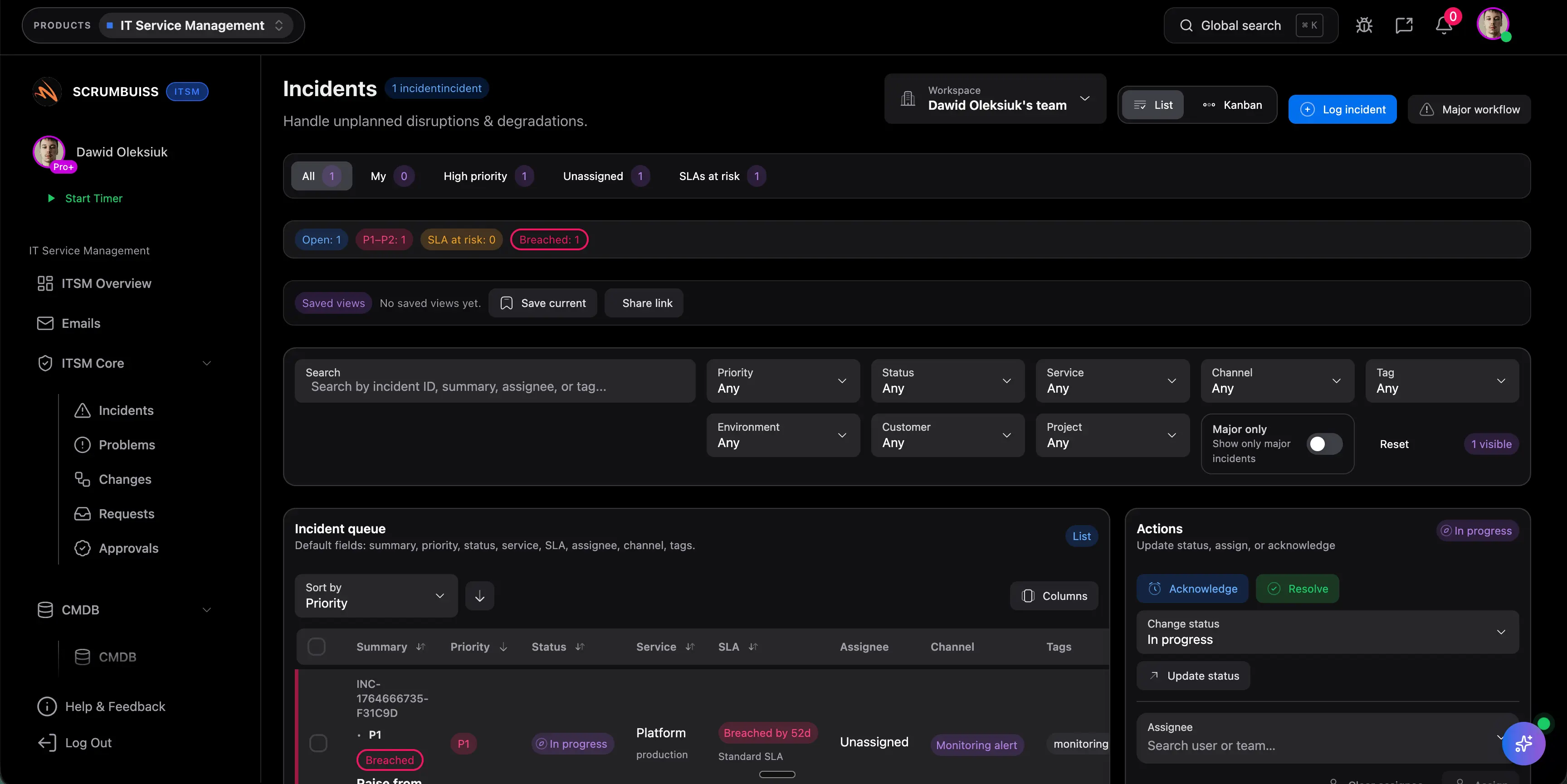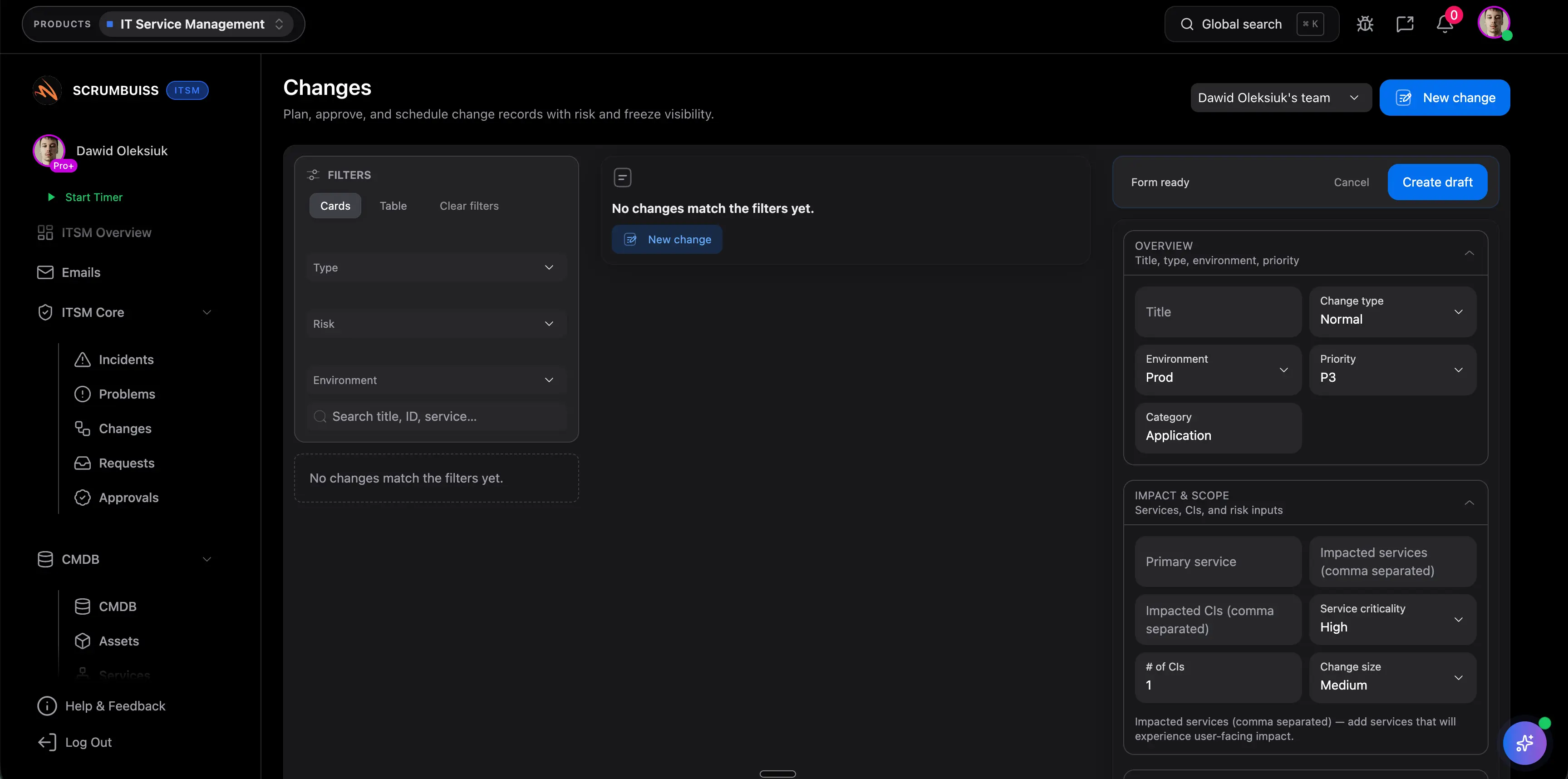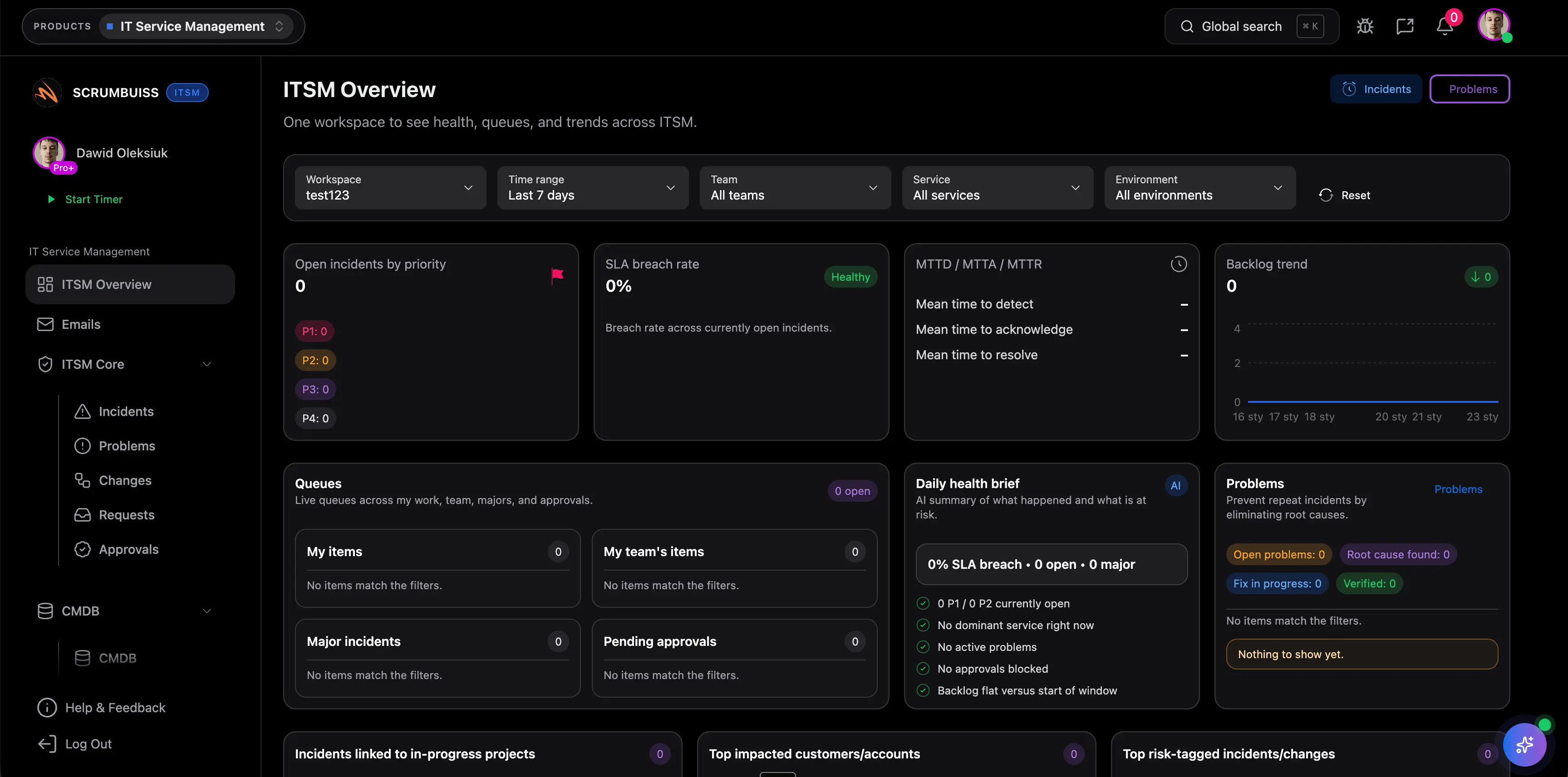
How we reviewed incident management software fit
Reviewed on May 19, 2026. This page evaluates whether incident management should live inside a broader ITSM and delivery workflow, instead of becoming a disconnected ticket queue, chat thread, or post-incident document.
- Scrumbuiss references come from the ITSM buyer guide, ITSM product page, IT operations use case, Slack integration, risk workflow, root cause analysis template, IT change management template, and incident postmortem template.
- We used the SEMrush export to separate incident management, service desk, ticketing, and change management intent from unrelated field-service or site-status-checker searches.
- The page keeps the promise narrow: triage, ownership, follow-up, operational visibility, and learning after incidents.